O Nex-N2 chegou forte no mercado de IA. O modelo combina raciocínio avançado, programação e uso de ferramentas, alcançando resultados que competem com GPT-5.5, Claude e DeepSeek em diversos benchmarks. Será que temos um novo gigante da inteligência artificial? #IA #OpenSource...
O Nex-N2 chegou forte no mercado de IA. O modelo combina raciocínio avançado, programação e uso de ferramentas, alcançando resultados que competem com GPT-5.5, Claude e DeepSeek em diversos benchmarks.
Será que temos um novo gigante da inteligência artificial?
#IA #OpenSource #NexN2 #shorts
⭐ Inscreva-se na Lista de Espera do Curso Pare de Brigar com a IA: https://app.horadecodar.com.br/lp/pare-de-brigar-com-a-ia-claude-code 🔴 Formação Vibe Coding (Antigravity, Claude Code e +): https://app.horadecodar.com.br/lp/formacao-vibe-coding?utm_source=yt_nexn2 🟪...
⭐ Inscreva-se na Lista de Espera do Curso Pare de Brigar com a IA: https://app.horadecodar.com.br/lp/pare-de-brigar-com-a-ia-claude-code
🔴 Formação Vibe Coding (Antigravity, Claude Code e +): https://app.horadecodar.com.br/lp/formacao-vibe-coding?utm_source=yt_nexn2
🟪 Hospedagem que eu indico: https://www.hostinger.com/battisti (use o cupom HORADECODAR para ter +10% de desconto)
📘 Guia Engenharia de Prompt: https://app.horadecodar.com.br/ebookpages/guia-engenharia-de-prompt
Entre no nosso servidor de Discord e me siga nas redes:
🟣 Discord Hora de Codar: https://discord.gg/Veq4mvsWwk
🔴 Instagram: https://www.instagram.com/horadecodar/
Nex-N2 é o novo modelo de IA open source lançado pelo lab chinês Nex AGI que chega prometendo bater o Claude e o GPT-5.5 em programação, e o melhor: está disponível de graça por tempo limitado. É um modelo agêntico, pensado pra código, uso de ferramentas e tarefas longas de verdade, e nesse vídeo eu testo na prática se ele entrega o que os benchmarks prometem, construindo com ele dentro do Claude Code e usando ele também como cérebro de visão de um app real.
Se você acompanha modelos de IA, gosta de open source e quer testar uma alternativa grátis aos modelos pagos sem perder qualidade, esse vídeo é pra você. O Nex-N2 entra na mesma onda que já vimos com Kimi, GLM, DeepSeek e MiniMax: labs chineses soltando modelos open source poderosos que encaram os gigantes fechados por uma fração do custo, ou nesse caso, de graça enquanto a janela durar.
O Nex-N2 é um modelo Mixture of Experts com 397 bilhões de parâmetros no total, mas só 17 bilhões ativos por vez, o que deixa ele poderoso e ao mesmo tempo viável de rodar. Ele é construído sobre a base Qwen3.5, tem licença Apache 2.0 (uso livre, inclusive comercial), aceita texto e imagem (multimodal), e tem janela de contexto de 262 mil tokens, ou seja, lê projeto grande inteiro de uma vez. Ele vem em duas versões: o Nex-N2-Pro, mais forte, e o Nex-N2-mini, mais leve pra hardware modesto.
Nos benchmarks é onde a história fica interessante. O Nex-N2-Pro marca 75.3 no Terminal-Bench 2.1, passando o Claude Opus 4.7 que fez 69.7. No SWE-Bench Verified ele faz 80.8, e no SWE-Bench Pro 58.8, praticamente empatando com o GPT-5.5. Em produtividade de mundo real (GDPval) ele pontua alto também. Na prática, são números de modelo de ponta vindos de um modelo que você pode baixar e usar sem pagar nada.
Mas aqui entra a parte honesta, que eu sempre faço questão de trazer: esses benchmarks são autorreportados pelo próprio lab, rodados no harness deles, e a comparação é contra o Opus 4.7, não contra o Opus 4.8 que já saiu. Ou seja, são números que ainda precisam de validação independente. É exatamente por isso que eu não fico só na tabela: eu boto o Nex-N2 pra trabalhar de verdade no vídeo e mostro onde ele entrega e onde ele tropeça, sem maquiar.
Um diferencial técnico interessante do Nex-N2 é o Adaptive Thinking, ou pensamento adaptativo. Ao invés de gastar tokens pensando fundo em tudo, ele decide sozinho quando vale raciocinar mais e quando pode ir direto, economizando de 30 a 50% dos tokens de raciocínio sem perder qualidade. Isso importa porque modelo que pensa demais à toa fica caro e lento, e o Nex tenta resolver isso de forma inteligente.
O ponto de acesso e urgência: o Nex-N2 está rodando de graça no OpenRouter por duas semanas a partir de 9 de junho de 2026, então a janela pra testar sem pagar nada é curta e fecha por volta de 23 de junho. Ele é plug and play com Claude Code, Cursor, OpenClaw e outras ferramentas agênticas, então dá pra plugar no teu fluxo atual e testar sem trocar de ambiente. Depois da janela grátis, continua acessível por uso pago, mas a centavos, por ser open source.
Resumindo a posição do Nex-N2 no cenário: é mais um sinal forte de que o open source alcançou a fronteira nas tarefas que o desenvolvedor realmente usa no dia a dia, programação, uso de ferramentas e trabalho agêntico longo. Não é só mais um modelo de chat, é um modelo feito pra agir, e o fato de ser grátis nessa janela torna ele obrigatório de testar agora.
E você, já testou o Nex-N2 ou ainda tá só nos modelos pagos? Comenta aqui embaixo qual modelo open source você quer ver no canal em seguida. Deixa o like, se inscreve no canal e ativa o sininho pra não perder os próximos vídeos sobre modelos open source, Claude Code e ferramentas de IA.
LINKS
Nex-N2 no GitHub: https://github.com/nex-agi/Nex-N2
Nex-N2-Pro no OpenRouter (grátis por tempo limitado): https://openrouter.ai/nex-agi/nex-n2-pro:free
TIMESTAMPS
00:00 Lançamento do novo modelo Nex-N2
01:24 Como usar o Nex-N2 de forma gratuita
04:30 Iniciando projeto com Nex-N2 no Claude Code
08:05 Integrando IA no projeto (usando Nex-N2 como IA)
12:25 Ampliando projeto com funcionalidade de histórico
15:10 Colocando o projeto no GitHub (iniciando deploy)
17:00 Escolhendo hospedagem para o projeto e colocando no ar
20:25 Benchmarks e análises do Nex-N2
23:00 Considerações finais do Nex-N2
Já imaginou uma IA capaz de analisar e organizar tudo o que aconteceu nos seus últimos 30 dias? Neste vídeo eu mostro o Last30Days, uma ferramenta que transforma seu histórico de atividades em insights úteis, ajudando a entender hábitos, produtividade e padrões que...
Já imaginou uma IA capaz de analisar e organizar tudo o que aconteceu nos seus últimos 30 dias? Neste vídeo eu mostro o Last30Days, uma ferramenta que transforma seu histórico de atividades em insights úteis, ajudando a entender hábitos, produtividade e padrões que normalmente passam despercebidos.
#IA #Last30Days #Produtividade #shorts
⭐ Inscreva-se na Lista de Espera do Curso Pare de Brigar com a IA: https://app.horadecodar.com.br/lp/pare-de-brigar-com-a-ia-claude-code 🔴 Formação Vibe Coding (Antigravity, Claude Code e +): https://app.horadecodar.com.br/lp/formacao-vibe-coding?utm_source=yt_proj_deepclaude...
⭐ Inscreva-se na Lista de Espera do Curso Pare de Brigar com a IA: https://app.horadecodar.com.br/lp/pare-de-brigar-com-a-ia-claude-code
🔴 Formação Vibe Coding (Antigravity, Claude Code e +): https://app.horadecodar.com.br/lp/formacao-vibe-coding?utm_source=yt_proj_deepclaude
🟪 Hospedagem do projeto de DeepClaude: https://hostinger.com.br/battisti (use o cupom HORADECODAR para ter +10% de desconto)
📘 Guia Engenharia de Prompt: https://app.horadecodar.com.br/ebookpages/guia-engenharia-de-prompt
Entre no nosso servidor de Discord e me siga nas redes:
🟣 Discord Hora de Codar: https://discord.gg/Veq4mvsWwk
🔴 Instagram: https://www.instagram.com/horadecodar/
Construir um app full-stack inteiro com DeepSeek no Claude Code, do zero ao deploy, gastando só centavos, é o que esse vídeo mostra na prática. A ideia é simples e é o que tá no hype agora: o DeepSeek entrega qualidade de modelo caro por uma fração do preço, e dá pra usar ele dentro do Claude Code que você já conhece, sem conta da Anthropic, sem mensalidade alta. Neste vídeo eu construo um SaaS completo com login, IA reescrevendo texto, histórico por usuário e deploy real, usando a técnica do PRD pra IA planejar antes de codar.
Se você viu o vídeo do DeepClaude e quer ver o DeepSeek indo além de um chat, ou se você sente o custo dos modelos fechados e quer uma alternativa barata sem perder qualidade, esse vídeo é pra você. É o mesmo setup do DeepClaude (mesma chave, mesmo settings.json, zero vínculo com Anthropic), agora aplicado pra construir e publicar um produto de verdade.
O conceito central ensinado aqui é o spec-driven com PRD. Ao invés de pedir "faz um app" e torcer pro resultado sair coerente, o primeiro prompt faz a IA escrever um PRD completo num arquivo, documentando visão, funcionalidades, telas, regras de cada formato, stack e ordem de construção. Os outros prompts de build ficam curtos porque a descrição concreta mora no PRD. Esse é o pulo do gato: PRD detalhado no começo gera prompts curtos depois e um app que sai consistente, com telas batendo com o modelo de dados e regras sendo respeitadas.
A stack usada é Next.js no frontend e backend, DeepSeek pela API sendo chamado sempre no servidor (a chave nunca fica exposta no navegador), Supabase pra login e histórico, e deploy via GitHub numa hospedagem Node. Você aprende a montar cada camada em sequência: primeiro a interface seguindo o PRD, depois a conexão com o DeepSeek, depois as regras de escrita de cada formato, depois autenticação, depois histórico por usuário, e por fim o deploy.
O app construído no vídeo é um adaptador de texto pra redes sociais: você cola um conteúdo, indica o formato de origem e escolhe pra quais formatos quer adaptar, e a IA reescreve respeitando a regra de cada um. LinkedIn com o padrão certo de espaçamento e tom, X com versão em thread quando o texto é longo, email com assunto provocativo, blog com SEO, descrição de YouTube com gancho nas duas primeiras linhas, e Instagram com bloco de hashtags. O diferencial é que a IA não só reescreve, reescreve seguindo o padrão definido no PRD.
No quesito segurança, o vídeo ensina o caminho certo: a chave do DeepSeek e as credenciais do Supabase ficam num arquivo .env que nunca sobe pro GitHub, e na hora do deploy os valores são recadastrados direto no painel da hospedagem. Nenhum segredo é versionado, nada de chave exposta no repositório.
A parte de autenticação cobre login e cadastro com Supabase, com proteção de rota (quem não tá logado não acessa o app), sessão que persiste ao recarregar a página, e cada usuário enxergando só o próprio histórico. O histórico salva cada transformação com formato de origem, início do texto, data e quantidade de formatos gerados, com ação de reabrir e de excluir.
O fechamento é a prova real do hype: abrir o dashboard do DeepSeek e mostrar quanto custou construir e rodar o app inteiro. Centavos. Feito pelo DeepSeek, rodando no DeepSeek, e o preço comprova que dá pra ter qualidade de modelo caro pagando quase nada.
Os aprendizados transferíveis pro seu fluxo: como usar a técnica do PRD pra qualquer projeto, como conectar o DeepSeek de forma segura no servidor, como adicionar login e dados por usuário com Supabase, e como fazer deploy via GitHub sem vazar credencial. O app é só o exemplo, a técnica serve pra qualquer SaaS.
TIMESTAMPS
00:00 DeepClaude para projetos: DeepSeek + Claude Code
01:12 O que é o DeepClaude?
04:27 Configurando o DeepClaude no Claude Code
06:16 Criando um PRD com o DeepClaude
09:15 Iniciando o projeto com DeepSeek + Claude Code
12:55 Integração com IA no projeto
15:40 Criando autenticação para projeto e integrando ao Supabase
19:00 Testando projeto com autenticação
21:18 Criando histórico de postagens do sistema
24:20 Colocando o projeto no GitHub
26:05 Iniciando o deploy do projeto (Colocando no ar o sistema)
29:40 Teste do projeto de DeepClaude no ar e últimas considerações
⭐ Inscreva-se na Lista de Espera do Curso Pare de Brigar com a IA: https://app.horadecodar.com.br/lp/pare-de-brigar-com-a-ia-claude-code 🔴 Formação Vibe Coding (Antigravity, Claude Code e +): https://app.horadecodar.com.br/lp/formacao-vibe-coding?utm_source=yt_last30d 🟪...
⭐ Inscreva-se na Lista de Espera do Curso Pare de Brigar com a IA: https://app.horadecodar.com.br/lp/pare-de-brigar-com-a-ia-claude-code
🔴 Formação Vibe Coding (Antigravity, Claude Code e +): https://app.horadecodar.com.br/lp/formacao-vibe-coding?utm_source=yt_last30d
🟪 Hospedagem que eu indico: https://www.hostinger.com/matheushoradecodar (use o cupom HORADECODAR para ter +10% de desconto)
📘 Guia Engenharia de Prompt: https://app.horadecodar.com.br/ebookpages/guia-engenharia-de-prompt
Entre no nosso servidor de Discord e me siga nas redes:
🟣 Discord Hora de Codar: https://discord.gg/Veq4mvsWwk
🔴 Instagram: https://www.instagram.com/horadecodar/
A skill /last30days transforma o Claude Code num pesquisador que vasculha Reddit, X, YouTube e mais de 14 plataformas em paralelo e te entrega um briefing único e citado sobre qualquer assunto, em poucos minutos. É a skill número 1 do GitHub no momento, open source, e resolve um problema que pouca gente percebe: nenhuma IA enxerga essas fontes nativamente. O ChatGPT não busca no X, o Gemini não lê o Reddit, o Claude não acessa nada disso sozinho. A /last30days conecta tudo e usa um agente pra sintetizar a opinião real da comunidade num relatório só.
Se você usa Claude Code e quer pesquisar de verdade, indo além do que o Google mostra, essa skill é pra você. A diferença central é o critério: o Google ranqueia por SEO, e quem manja de SEO sobe, mesmo sem ter razão. A /last30days ranqueia por engajamento real, ou seja, upvotes do Reddit, likes, discussão de verdade, e até dinheiro apostado no Polymarket. É a diferença entre ler um blog otimizado pra ranquear e ouvir o que as pessoas realmente estão falando.
A instalação é zero config. No Claude Code é só adicionar o marketplace da skill e instalar, dois comandos e pronto. As fontes principais já funcionam sem nenhuma chave de API: Reddit com comentários, Hacker News, Polymarket e GitHub saem da caixa. A skill também roda em outros hosts além do Claude Code (Codex, Cursor, Copilot, Gemini CLI e mais de 50 ambientes) e dá pra usar no claude.ai web também, pra quem não usa o terminal.
O uso é simples: você digita /last30days seguido do assunto, e a skill dispara vários agentes que buscam em paralelo, leem as discussões e devolvem um briefing organizado. Em vez de você abrir dez abas e ler trinta threads, recebe a síntese com as citações pra conferir a fonte. E como o training data de qualquer IA está sempre meses atrasado, a /last30days preenche esse buraco: a comunidade sabe das coisas primeiro, e a skill traz isso fresco.
Os casos de uso são amplos. Pra saber se um modelo de IA recém-lançado presta de verdade, ela traz as threads do Reddit com opinião real contra o hype, mais benchmarks independentes da comunidade. Pra decidir entre duas ferramentas, tipo Cursor contra Claude Code, ela roda a comparação em passe único e monta uma tabela lado a lado com dados ao vivo do GitHub, incluindo reclamações recentes de preço e plano que review nenhum mostra. Tem até uma flag que descobre os concorrentes sozinha e roda uma comparação de três frentes.
E não serve só pra dev. Antes de comprar um produto, ela acha as reclamações reais que a loja esconde, problemas recentes de driver ou hardware, e o consenso da comunidade. Vale pra placa de vídeo, celular, banco, ou até pra pesquisar uma empresa antes de uma entrevista. Qualquer decisão que se beneficia de saber o que as pessoas reais andam falando nos últimos 30 dias.
Algumas fontes precisam de um setup rápido que a própria skill guia. Na primeira execução, um assistente roda sozinho, detecta o que falta e oferece configurar automaticamente. Pro X, ela usa os cookies do navegador, de graça. Pro YouTube, basta ter o yt-dlp instalado e ela lê as transcrições completas dos vídeos. Pra TikTok, Instagram e Threads, dá pra plugar uma chave do ScrapeCreators que vem com créditos grátis. Com X e YouTube ativos, o briefing fica ainda mais completo.
Um recurso muito útil é a exportação. Você pode pedir o resultado como um arquivo HTML compartilhável, em dark mode, autocontido, com todas as citações, pronto pra mandar no Slack, Notion ou email. E tem um detalhe poderoso: depois de uma pesquisa, a própria sessão do Claude vira especialista no assunto, então dá pra pedir roteiro, prompts, emails ou qualquer coisa, tudo fundamentado no que a comunidade falou.
Pra fechar, a skill é MIT, open source e sem tracking, a pesquisa fica na sua máquina. E ainda dá pra montar monitoramento contínuo, com watchlist e briefing diário ou semanal automático, virando um radar de tendências.
E você, qual seria o primeiro assunto que você ia jogar na /last30days pra ver o que a comunidade anda falando? Comenta aqui embaixo. Deixa o like, se inscreve no canal e ativa o sininho pra não perder os próximos vídeos sobre Claude Code, skills e ferramentas de IA.
LINKS
/last30days no GitHub: https://github.com/mvanhorn/last30days-skill
E se você pudesse usar Claude Code, Cursor, Codex e outros agentes de IA gastando muito menos tokens sem perder qualidade? O Headroom é uma ferramenta open source que comprime automaticamente logs, arquivos, histórico de conversas e resultados de buscas antes de enviar tudo...
E se você pudesse usar Claude Code, Cursor, Codex e outros agentes de IA gastando muito menos tokens sem perder qualidade? O Headroom é uma ferramenta open source que comprime automaticamente logs, arquivos, histórico de conversas e resultados de buscas antes de enviar tudo para a IA. O resultado é menos custo, mais contexto disponível e respostas praticamente iguais. Além disso, ele funciona com vários agentes ao mesmo tempo e ainda cria uma memória compartilhada entre eles.
#IA #ClaudeCode #Headroom #shorts
✅ Experimente o Bitrix24 gratuitamente: https://www.bitrix24.com.br/~R3FDD Headroom é a ferramenta que corta de 60 a 95% dos tokens do Claude Code sem você mudar uma linha de código nem perder qualidade na resposta. Ele senta entre o seu agente e o LLM e comprime tudo que...
✅ Experimente o Bitrix24 gratuitamente: https://www.bitrix24.com.br/~R3FDD
Headroom é a ferramenta que corta de 60 a 95% dos tokens do Claude Code sem você mudar uma linha de código nem perder qualidade na resposta. Ele senta entre o seu agente e o LLM e comprime tudo que entra no contexto: tool output, logs, RAG, arquivos e histórico.
⭐ Inscreva-se na Lista de Espera do Curso Pare de Brigar com a IA: https://app.horadecodar.com.br/lp/pare-de-brigar-com-a-ia-claude-code
🔴 Formação Vibe Coding (Antigravity, Claude Code e +): https://app.horadecodar.com.br/lp/formacao-vibe-coding?utm_source=yt
🟪 Hospedagem que eu indico: https://www.hostinger.com/matheushoradecodar (use o cupom HORADECODAR para ter +10% de desconto)
📘 Guia Engenharia de Prompt: https://app.horadecodar.com.br/ebookpages/guia-engenharia-de-prompt
Entre no nosso servidor de Discord e me siga nas redes:
🟣 Discord Hora de Codar: https://discord.gg/Veq4mvsWwk
🔴 Instagram: https://www.instagram.com/horadecodar/
Roda local, é reversível, e ativa com um único comando. Neste vídeo eu mostro o antes e depois numa busca pesada de codebase, instalo o Headroom, ativo com o comando-herói, e revelo o número real de economia no dashboard.
Se você usa Claude Code todo dia e sente o contexto enchendo rápido (e o custo subindo junto), esse vídeo é pra você. O problema é conhecido: você pede pro agente buscar algo no projeto, ele traz um tool output gigante, isso enche o contexto e você paga por cada token disso. O Headroom resolve exatamente esse desperdício, comprimindo o que entra sem alterar o que o agente entende.
O recurso central é o comando headroom wrap claude. Ele envolve o Claude Code, e a partir daí tudo passa pelo Headroom automaticamente, sem você reconfigurar nada. O Claude Code abre normal, funciona igual, mas cada tool output que voltaria gigante chega comprimido. No vídeo eu rodo a mesma busca pesada antes e depois de ativar, e comparo o headroom stats lado a lado: a resposta é a mesma, o gasto de token é uma fração.
A grande sacada é que comprimir não significa perder. O Headroom usa compressão reversível (CCR): o conteúdo original fica guardado localmente, e quando o agente precisa de um detalhe que foi comprimido, ele chama o headroom_retrieve e recupera o original completo sob demanda. Você ganha a economia sem o risco de perder informação importante no meio do caminho.
Além da compressão, o Headroom tem o comando headroom learn, que minera as sessões que falharam e escreve correções direto no seu CLAUDE.md ou AGENTS.md. Na prática, o agente vai ficando melhor com o tempo, aprendendo com os próprios erros e documentando isso pra não repetir. E a memória é cross-agent: Claude, Codex e Gemini compartilham o mesmo contexto e memória, com deduplicação automática, então o aprendizado não fica preso a um único agente.
Pra quem não quer usar o wrap, existem modos alternativos. O modo proxy sobe um servidor local e serve qualquer cliente compatível só apontando o ANTHROPIC_BASE_URL pra ele, sem mudar código. Tem também o modo library, pra usar a compressão direto no seu código com um import, e o modo MCP, pra instalar como servidor MCP. Quatro formas de plugar o Headroom, da mais simples (wrap) à mais integrada (library).
A instalação é direta via pip (precisa Python 3.10 ou mais novo), e também tem versões via npm e docker. Depois de instalado, é um comando pra ativar e pronto.
Sendo honesto sobre quando vale: o Headroom faz sentido se você roda agente todo dia, usa vários agentes diferentes, ou precisa da compressão reversível pra não perder contexto. Não faz tanto sentido se você só usa a compactação nativa de um provider específico, ou se trabalha num ambiente sandboxed sem processo local rodando. Não é bala de prata, é ferramenta pra um perfil específico de uso intenso.
Os aprendizados transferíveis: como reduzir drasticamente o custo de rodar agentes de IA, como manter compressão sem perder reversibilidade, como fazer o agente aprender com os próprios erros via learn, e como compartilhar memória entre múltiplos agentes. Tudo open source.
E você, quanto você gasta hoje rodando Claude Code todo dia? Comenta aqui embaixo. Já usa alguma ferramenta de compressão de contexto ou tá pagando token cheio? Deixa o like, se inscreve no canal e ativa o sininho pra não perder os próximos vídeos sobre Claude Code, agentes IA e ferramentas open source.
LINKS
Headroom no GitHub: https://github.com/chopratejas/headroom
TIMESTAMPS
00:00 Como economizar tokens no Claude Code (Headroom)
00:35 Como funciona o Headroom
06:40 Instalando o Headroom
08:50 Executando o Headroom no Claude Code
10:40 Vendo economia de tokens após o Headroom
11:50 Fazendo o Headroom aprender com os erros e melhorar o projeto
14:50 Considerações finais sobre o Headroom
O DeepClaude é uma solução que une o raciocínio do DeepSeek com a qualidade de respostas do Claude AI. A proposta é usar o melhor dos dois modelos para gerar respostas mais precisas, melhorar programação, resolver problemas complexos e entregar resultados mais consistentes do...
O DeepClaude é uma solução que une o raciocínio do DeepSeek com a qualidade de respostas do Claude AI.
A proposta é usar o melhor dos dois modelos para gerar respostas mais precisas, melhorar programação, resolver problemas complexos e entregar resultados mais consistentes do que usar apenas uma IA sozinha.
#ia #deepseek #opensource #shorts
Printing Press é a fábrica que transforma qualquer site ou API em CLI agent-native pro Claude Code, com workflow até 10x mais rápido que MCP tradicional. Neste vídeo eu mostro a ferramenta completa: instalação do binário, carregamento das skills, uso de um CLI pronto da...
Printing Press é a fábrica que transforma qualquer site ou API em CLI agent-native pro Claude Code, com workflow até 10x mais rápido que MCP tradicional. Neste vídeo eu mostro a ferramenta completa: instalação do binário, carregamento das skills, uso de um CLI pronto da biblioteca de 52 disponíveis, e duas gerações do zero ao vivo, uma a partir de uma API documentada brasileira (Asaas) e outra a partir de um site sem API pública (OLX).
⭐ Inscreva-se na Lista de Espera do Curso Pare de Brigar com a IA: https://app.horadecodar.com.br/lp/pare-de-brigar-com-a-ia-claude-code
🔴 Formação Vibe Coding (Antigravity, Claude Code e +): https://app.horadecodar.com.br/lp/formacao-vibe-coding?utm_source=yt
🟪 Hospedagem que eu indico: https://www.hostinger.com/matheushoradecodar (use o cupom HORADECODAR para ter +10% de desconto)
📘 Guia Engenharia de Prompt: https://app.horadecodar.com.br/ebookpages/guia-engenharia-de-prompt
Entre no nosso servidor de Discord e me siga nas redes:
🟣 Discord Hora de Codar: https://discord.gg/Veq4mvsWwk
🔴 Instagram: https://www.instagram.com/horadecodar/
O conceito é poderoso: ao invés de carregar um MCP server pesado que consome token só pra existir no contexto, você usa um CLI enxuto que o agente sabe exatamente como chamar via skill.
Se você usa Claude Code todo dia, sente que MCPs estão pesando no contexto e quer parar de gastar token à toa, esse vídeo é pra você. Cubro o problema do MCP tradicional carregando 30 tools de uma vez, a sacada do Printing Press de gerar 4 outputs de uma só geração (binário Go standalone, skill Claude Code, skill OpenClaw e MCP server), e a parte brasileira gerando CLI pra Asaas e OLX em poucos minutos.
A instalação é direta: go install pra baixar o binário, git clone do repo de skills, claude com plugin-dir pra carregar tudo. As 5 slash commands aparecem no help: printing-press, polish, publish, reprint e import. O conjunto cobre o ciclo completo de uma fábrica de CLIs.
A primeira demo é o flight-goat, que junta Google Flights com Kayak nonstop sem precisar de API key. Rodo busca direta GRU para LHR, scan de range de datas pro mais barato, e mostro a flag agent que ativa json compact no-input no-color yes de uma vez. Esse é o argumento literal do vídeo: o CLI nasce desenhado pra agente, não adaptado pra agente. Termino chamando o flight-goat via prompt em PT-BR no Claude Code, que identifica a skill sozinho.
A segunda demo é gerar CLI do zero pro Asaas, gateway de pagamento brasileiro. Disparo o slash command passando só o nome da empresa, e o Claude Code roda 5 fases automaticamente: research lendo docs, discovery mapeando endpoints, code generation criando o Go CLI, verification rodando dogfood contra a spec, polish limpando e gerando README. No final tem quality score, dois binários (asaas-pp-cli e asaas-pp-mcp), e SKILL.md pronta. Crio conta sandbox em um minuto, exporto a API key como variável de ambiente e rodo customers list e payments list no terminal.
A terceira demo é o pulo do gato: gerar CLI pra um site brasileiro sem API pública. Aponto o printing-press pra URL do OLX, e a fábrica abre browser headless, sniffa o tráfego do front, identifica endpoints internos e parâmetros de paginação, gera CLI igual o do Asaas. Rodo busca de iPhone 15 em Santa Catarina, e chamo via Claude Code em PT-BR pedindo os 5 anúncios mais baratos em Florianópolis das últimas 24h. O mesmo padrão funciona pra Mercado Livre, Vagas, Quinto Andar, qualquer site brasileiro.
Mostro também os recursos extras: o modo Codex delega code generation pro Codex CLI mantendo o Claude como cérebro, economizando 60% dos tokens Opus. O polish roda diagnóstico completo e conserta falhas. E o publish empacota e abre PR automático na biblioteca pública, deixando você como autor, com convite pra ser o primeiro brasileiro a publicar.
Os casos de uso pro seu fluxo: transformar seu SaaS em CLI pro Claude Code chamar direto, virar site BR sem API em agente IA, substituir MCPs pesados liberando contexto, padronizar time inteiro com o mesmo CLI. Tudo open source, gratuito, funciona em Claude Code, Codex, OpenClaw e Hermes, e o autor é endossado publicamente pelo Garry Tan da Y Combinator.
E você, qual API ou site brasileiro quer ver virar CLI no Claude Code? Comenta aqui embaixo que o mais pedido eu gero ao vivo no próximo vídeo. Já testou alguma fábrica de CLI ou ainda usa MCP tradicional? Deixa o like, se inscreve no canal e ativa o sininho pra não perder os próximos drops do ecossistema Claude Code.
LINKS
Printing Press: https://printingpress.dev
TIMESTAMPS
00:00 Agora o Claude Code vai conseguite integrar com qualquer serviço!
01:25 Como funciona o Printing Press
03:10 Instalando o Printing Press
09:10 Utilizando o Printing Press
15:24 Criando um CLI com o Printing Press (Exemplo Asaas)
18:25 Criando CLI do OLX para buscar produtos
21:30 Testando os CLIs criados com o Printing Press
25:00 Considerações finais sobre o Printing Press
✅ DESCONTO DE 12% no MiniMax: https://platform.minimax.io/subscribe/coding-plan?code=2XYVmDkIK5&source=link MiniMax Platform: https://platform.minimax.io Documentação do MiniMax: https://platform.minimax.io/docs/guides/text-generation ⭐ Inscreva-se na Lista de Espera do Curso...
✅ DESCONTO DE 12% no MiniMax: https://platform.minimax.io/subscribe/coding-plan?code=2XYVmDkIK5&source=link
MiniMax Platform: https://platform.minimax.io
Documentação do MiniMax: https://platform.minimax.io/docs/guides/text-generation
⭐ Inscreva-se na Lista de Espera do Curso Pare de Brigar com a IA: https://app.horadecodar.com.br/lp/pare-de-brigar-com-a-ia-claude-code
🔴 Formação Vibe Coding (Antigravity, Claude Code e +): https://app.horadecodar.com.br/lp/formacao-vibe-coding?utm_source=yt
🟪 Hospedagem que eu indico: https://www.hostinger.com/matheushoradecodar (use o cupom HORADECODAR para ter +10% de desconto)
📘 Guia Engenharia de Prompt: https://app.horadecodar.com.br/ebookpages/guia-engenharia-de-prompt
Entre no nosso servidor de Discord e me siga nas redes:
🟣 Discord Hora de Codar: https://discord.gg/Veq4mvsWwk
🔴 Instagram: https://www.instagram.com/horadecodar/
MiniMax M3 é o modelo open-weight lançado dia 1 de junho que junta três frontiers num modelo só: código forte, 1 milhão de tokens de contexto e multimodalidade nativa, tudo rodando dentro do Claude Code que você já usa, por uma fração do custo de um modelo fechado de ponta. Neste vídeo eu mostro como plugar o M3 no Claude Code, construo um app full-stack do zero em fluxo spec-driven (o próprio modelo escreve o PRD e constrói a partir dele), e no final faço o teste que modelo só de texto não passa: fotografar uma nota fiscal e deixar o M3 ler a imagem e extrair os dados sozinho.
Se você usa Claude Code todo dia e quer testar um modelo open-weight poderoso sem trocar de ferramenta, ou busca alternativa mais barata pros modelos fechados sem abrir mão de capacidade, esse vídeo é pra você. O MiniMax M3 é o primeiro open-weight a combinar coding de alto nível, contexto de 1 milhão de tokens e leitura de imagem nativa ao mesmo tempo, o que abre uma faixa de casos de uso que antes exigia juntar vários modelos diferentes.
A grande sacada técnica do M3 é a arquitetura MSA, que deixa o contexto longo barato de processar (prefill cerca de 9 vezes mais eficiente e decoding cerca de 15 vezes). Na prática isso significa rodar tarefas longas e contexto gigante sem o custo explodir. Pra dar dimensão, um dos destaques de lançamento foi o modelo rodar 12 horas sozinho reproduzindo um paper do ICLR.
A integração com o Claude Code é direta: você ajusta o settings.json apontando o ANTHROPIC_BASE_URL pra API da MiniMax no formato Anthropic, cola a API key, e define o MiniMax-M3 como modelo padrão. A partir daí, tudo que o Claude Code faz roda no M3. A chave sai da plataforma da MiniMax, e o vídeo mostra o passo a passo completo, incluindo o cuidado de dar unset nas variáveis de ambiente que têm prioridade sobre o arquivo.
O diferencial do vídeo é o fluxo spec-driven. Ao invés de pedir "faz um app" e torcer, eu peço pro M3 agir como engenheiro de produto sênior e escrever um PRD completo primeiro, com problema, escopo do MVP, features priorizadas, modelo de dados, contratos de API, fluxos, telas e critérios de aceite. Esse PRD vira o documento que amarra todos os próximos passos. A qualidade do spec gerado é o que faz o build sair coerente, com telas batendo com o modelo de dados e rotas batendo com os contratos.
A partir do PRD, o M3 constrói o app NotaFlow em etapas: primeiro o frontend em Next.js com App Router, TypeScript e Tailwind, com dados mockados respeitando o modelo de dados do spec. Depois a camada de persistência com Prisma e SQLite, criando os models exatamente como definido no PRD, gerando migration e implementando as rotas de API. Cada etapa puxa do spec ao invés de inventar.
O momento mais impressionante é a leitura multimodal. O M3 implementa uma rota que recebe a foto de uma nota fiscal em base64, manda pra própria API multimodal do modelo, e extrai estabelecimento, valor total, data e categoria num JSON estruturado. Você fotografa a nota, o modelo lê a imagem, preenche o formulário pra revisar, confirma, e o gasto aparece no dashboard. Imagem entra, dado estruturado sai. Multimodalidade nativa, algo que modelo só de texto não faz.
Sobre benchmarks, sendo transparente: no SWE-Bench Pro o M3 marca 59.0, atrás do Opus 4.7 e do Opus 4.8, mas na frente do GPT-5.5. No BrowseComp ele faz 83.5, passando o Opus 4.7. O M3 não é o melhor do mundo em código puro, mas construiu um app full-stack spec-driven com leitura multimodal por uma fração do preço, rodando no Claude Code. E vários benchmarks foram rodados na infra da própria MiniMax, então validar no caso real, como fiz aqui, conta mais que tabela.
O acesso vem via Token Plan em três tiers (Plus, Max e Ultra), com pool único que dá acesso à família toda de modelos da MiniMax, incluindo M3, imagem, fala e música. Tem cupom de desconto pra audiência do canal em todos os tiers, e também dá pra usar via OpenRouter com preço promocional.
E você, qual modelo open-weight você quer ver rodando no Claude Code em seguida? Comenta aqui embaixo!
#MiniMax #MiniMaxM3
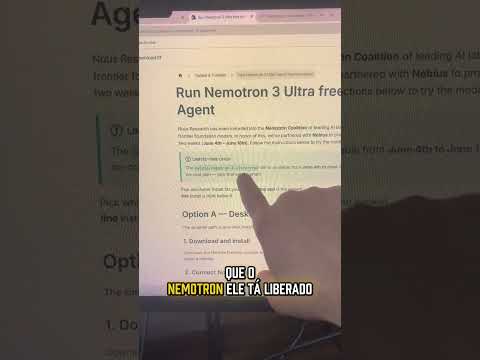
A Hermes Agent liberou acesso gratuito ao modelo Nemotron 3 Ultra por tempo limitado. Basta conectar sua conta ao Nous Portal, selecionar a versão nvidia/nemotron-3-ultra:free e começar a usar um dos modelos mais avançados da NVIDIA sem custo. A oferta é válida até 18 de...
A Hermes Agent liberou acesso gratuito ao modelo Nemotron 3 Ultra por tempo limitado.
Basta conectar sua conta ao Nous Portal, selecionar a versão nvidia/nemotron-3-ultra:free e começar a usar um dos modelos mais avançados da NVIDIA sem custo.
A oferta é válida até 18 de junho, tanto no aplicativo desktop quanto na versão de terminal do Hermes.
#ia #hermesagent #opensource #shorts
⭐ Inscreva-se na Lista de Espera do Curso Pare de Brigar com a IA: https://app.horadecodar.com.br/lp/pare-de-brigar-com-a-ia-claude-code 🔴 Formação Vibe Coding (Antigravity, Claude Code e +): https://app.horadecodar.com.br/lp/formacao-vibe-coding?utm_source=yt 🟪 Hospedagem...
⭐ Inscreva-se na Lista de Espera do Curso Pare de Brigar com a IA: https://app.horadecodar.com.br/lp/pare-de-brigar-com-a-ia-claude-code
🔴 Formação Vibe Coding (Antigravity, Claude Code e +): https://app.horadecodar.com.br/lp/formacao-vibe-coding?utm_source=yt
🟪 Hospedagem que eu indico: https://www.hostinger.com/matheushoradecodar (use o cupom HORADECODAR para ter +10% de desconto)
Claude Fable 5 é o novo modelo da Anthropic e o mais forte que eles já liberaram pro público, uma classe inteira acima do Opus, com desempenho de ponta em programação, trabalho autônomo de longa duração, visão, raciocínio e pesquisa científica. É a primeira vez que a Anthropic libera um modelo dessa classe de capacidade pra qualquer pessoa usar, e a regra de ouro dele é clara: quanto mais longa e complexa a tarefa, maior a vantagem do Fable sobre todos os outros modelos.
O Fable 5 é um modelo Mythos-class. Isso quer dizer que ele é da mesma família do Claude Mythos 5, o modelo mais poderoso da Anthropic, que fica restrito a parceiros de cibersegurança e ao governo através do Project Glasswing. O Fable 5 e o Mythos 5 são o mesmo modelo por baixo, a única diferença são os safeguards: o Mythos roda sem a trava de cyber e fica só pro programa Glasswing, enquanto o Fable vem com travas de segurança ativas e por isso pode ser liberado pra todo mundo. Na prática, você tem acesso à mesma classe de capacidade do modelo mais forte da empresa, com proteções que tornam o uso seguro.
As capacidades do Fable 5 são estado da arte em quase todos os benchmarks de IA testados. Em engenharia de software ele dá um salto sobre os modelos anteriores: a Stripe relatou que o Fable 5 completou uma migração de uma base de código Ruby de dezenas de milhões de linhas em um único dia, um trabalho que levaria um time inteiro mais de dois meses fazendo na mão. Em visão, ele consegue reconstruir o código de um aplicativo só olhando um print de tela, e em testes mais extremos chegou a completar um jogo inteiro apenas a partir de screenshots. E em memória de longo prazo, mantendo contexto ao longo de tarefas gigantes, ele performa várias vezes melhor que o Opus.
O grande diferencial do Fable 5 é a capacidade agêntica de longa duração. Ele mantém o fio de uma tarefa complexa por muitos turnos sem se perder, consulta o próprio planejamento, se recupera de erros sozinho e segue trabalhando até concluir. É por isso que ele brilha em construções longas no estilo agente, onde modelos anteriores costumam perder contexto, repetir passos ou precisar de empurrão manual. Quanto maior e mais demorada a tarefa, mais a diferença aparece.
Um ponto importante de entender é o sistema de fallback de segurança. O Fable 5 tem travas em três áreas sensíveis: cibersegurança, biologia e química, e distillation de modelo. Quando um pedido cai numa dessas áreas, a resposta não vem do Fable, vem do Claude Opus 4.8, e o usuário é avisado disso. Esse comportamento acontece, em média, em menos de 5% das sessões, e as travas foram calibradas de forma conservadora, então às vezes elas pegam até pedidos inofensivos. Pra mais de 95% do uso real, é zero diferença, você usa o Fable 5 do começo ao fim. É um diferencial de acesso responsável, não uma limitação no uso comum.
Sobre preço, o Fable 5 custa 10 dólares por milhão de tokens de entrada e 50 dólares por milhão de tokens de saída, menos da metade do que era cobrado no Mythos Preview. Na API da Anthropic ele é acessado pelo identificador claude-fable-5. Ele também está incluído nos planos Pro, Max, Team e Enterprise.
Tem um detalhe de acesso que vale ficar de olho: o Fable 5 está disponível de graça nesses planos até 22 de junho de 2026. A partir de 23 de junho, pode passar a exigir usage credits enquanto a Anthropic expande a capacidade, já que a demanda esperada é alta. Ou seja, a janela pra testar sem custo adicional é curta, e quem quiser experimentar o modelo mais forte da empresa de graça deve aproveitar agora.
Resumindo a posição do Fable 5 no ecossistema: é o topo do que a Anthropic oferece publicamente, uma classe acima do Opus 4.8, pensado pra quem trabalha com tarefas longas, automação, código complexo e raciocínio pesado. Não substitui o Opus em tudo (em pedidos sensíveis o próprio fallback usa o Opus), mas pra trabalho autônomo de verdade, é o modelo mais capaz que você consegue acessar hoje.
E você, qual tarefa longa você vai jogar no Fable 5 pra ver até onde ele vai sozinho? Comenta aqui embaixo. Já testou ou ainda tá no Opus? Deixa o like, se inscreve no canal e ativa o sininho pra não perder os próximos vídeos sobre Claude!
LINKS
Anúncio oficial do Claude Fable 5 e Mythos 5: https://www.anthropic.com/news/claude-fable-5-mythos-5
TIMESTAMPS
00:00 Anthropic Lançou o Claude Fable 5!
00:37 Diferenciais e recursos do Claude Fable 5
05:30 Como usar o Claude Fable 5
07:10 Testando o Claude Fable 5 no Claude Code
10:20 Resultados do teste Claude Fable 5
12:30 Minhas considerações sobre o Fable 5
⭐ Inscreva-se na Lista de Espera do Curso Pare de Brigar com a IA: https://app.horadecodar.com.br/lp/pare-de-brigar-com-a-ia-claude-code 🟪 Hospedagem para Hermes Agent: https://www.hostinger.com/matheushoradecodar (use o cupom HORADECODAR para ter +10% de desconto) 🔴 Formação...
⭐ Inscreva-se na Lista de Espera do Curso Pare de Brigar com a IA: https://app.horadecodar.com.br/lp/pare-de-brigar-com-a-ia-claude-code
🟪 Hospedagem para Hermes Agent: https://www.hostinger.com/matheushoradecodar (use o cupom HORADECODAR para ter +10% de desconto)
🔴 Formação Vibe Coding (Antigravity, Claude Code e +): https://app.horadecodar.com.br/lp/formacao-vibe-coding?utm_source=yt
📘 Guia Engenharia de Prompt: https://app.horadecodar.com.br/ebookpages/guia-engenharia-de-prompt
Entre no nosso servidor de Discord e me siga nas redes:
🟣 Discord Hora de Codar: https://discord.gg/Veq4mvsWwk
🔴 Instagram: https://www.instagram.com/horadecodar/
Hermes é o agente de IA que roda no terminal e que você pode usar de graça, plugando nele modelos de ponta sem precisar de uma máquina poderosa. Neste vídeo eu mostro como rodar o Hermes sem pagar nada usando como cérebro o Nemotron 3 Ultra, o novo modelo gigante da NVIDIA com 550 bilhões de parâmetros, que normalmente seria coisa de datacenter. E mostro ao vivo a pegadinha que ninguém comenta sobre esse "grátis", batendo no limite na frente da câmera.
Se você curte agentes de IA, ferramentas open source e quer botar um agente pra trabalhar de graça, esse vídeo é pra você. A ideia central é simples: o Hermes não te prende a um modelo só nem te obriga a pagar. Você aponta ele pro provedor que quiser e usa o modelo que quiser, inclusive um monstro de 550B, gastando zero enquanto estiver no tier gratuito.
O Hermes é o agente da Nous Research que vive no terminal. Ele executa tarefas, usa ferramentas, mexe em arquivos e roda comandos, no estilo de um agente autônomo de verdade, parecido com o Claude Code mas open source e flexível na escolha de modelo. É isso que faz ele tão interessante pra rodar de graça: como ele aceita qualquer modelo via API compatível, você não fica refém de uma assinatura, escolhe o caminho que cabe no teu bolso.
O modelo que eu pluguei pra demonstrar foi o Nemotron 3 Ultra, o lançamento gigante da NVIDIA com 550 bilhões de parâmetros, focado em raciocínio e em agentes de longa duração. Esse modelo não roda no seu PC, nem na minha RTX 4070 Ti, porque é escala de datacenter. Então o caminho não é local, é via API, e é aí que entra o pulo do gato: dá pra acessar esse cérebro gigante de graça enquanto estiver no tier gratuito de um provedor como o OpenRouter, colocando um modelo de ponta pra controlar o agente sem custo nenhum.
No vídeo eu mostro o passo a passo completo pra deixar o Hermes rodando de graça: criar a conta no OpenRouter, gerar a API key, configurar essa chave no Hermes apontando pro Nemotron 3 Ultra, e rodar uma tarefa agêntica de verdade. Você vê o agente em ação, usando ferramentas, executando os passos, com um modelo de 550B por trás, tudo sem tirar o cartão do bolso.
Agora a parte que ninguém mostra nos vídeos de IA grátis, e que é o meu diferencial de sempre falar a real: o tier gratuito tem limite. São cerca de 50 requisições por dia, e um agente queima isso num piscar de olhos, porque cada passo de raciocínio e cada uso de ferramenta consome requisição. Então o Hermes grátis é perfeito pra testar, aprender e validar se vale pro teu caso, mas não aguenta um uso intenso de agente o dia inteiro. Eu mostro isso ao vivo, batendo no teto enquanto uso, pra você não cair na ilusão do grátis ilimitado.
Pra quem quer usar o Hermes pra valer, mostro os dois caminhos sérios no final. O primeiro é o OpenRouter pago, onde você passa a pagar por uso e some o limite do tier gratuito. O segundo é o Nous Portal, o acesso oficial pra usar os modelos com mais folga. A lógica é direta: testar de graça é ótimo pra validar, mas se for produção, você precisa saber exatamente o que está pagando.
Os aprendizados transferíveis: como deixar o Hermes rodando sem pagar, como plugar qualquer modelo do OpenRouter dentro dele, como usar um modelo gigante que você não conseguiria hospedar localmente, e como avaliar se um tier gratuito serve pro teu uso real antes de levar um agente pra produção. Vale pro Nemotron e pra qualquer outro modelo que você queira testar no Hermes pelo mesmo caminho.
E você, já botou um agente de IA pra rodar de graça ou ainda acha que precisa pagar pra usar agente? Comenta aqui embaixo qual modelo você quer ver rodando no Hermes em seguida. Deixa o like, se inscreve no canal e ativa o sininho pra não perder os próximos vídeos sobre agentes de IA, modelos open source e ferramentas no terminal.
TIMESTAMPS
00:00 Como rodar o Hermes Agent de graça
01:12 Conhecendo o modelo gratuito para rodar Hermes (Nemotron 3 Ultra)
02:12 Instalando o Hermes Agent
05:50 Configurando Nemotron Ultra 3 Gratuito no Hermes Agent
09:30 Considerações finais sobre Hermes Agent
Manifest é o roteador de LLM open source que decide automaticamente qual modelo usar pra cada task do Claude Code, cortando até 70% do gasto mensal sem você reescrever uma linha de código. ⭐ Inscreva-se na Lista de Espera da Formação Codex Master:...
Manifest é o roteador de LLM open source que decide automaticamente qual modelo usar pra cada task do Claude Code, cortando até 70% do gasto mensal sem você reescrever uma linha de código.
⭐ Inscreva-se na Lista de Espera da Formação Codex Master: https://app.horadecodar.com.br/lp/esquenta-codex-master
🔴 Formação Vibe Coding (Antigravity, Claude Code e +): https://app.horadecodar.com.br/lp/formacao-vibe-coding?utm_source=yt_manifest
🟪 Hospedagem que eu indico: https://www.hostinger.com/matheushoradecodar (use o cupom HORADECODAR para ter +10% de desconto)
📘 Guia Engenharia de Prompt: https://app.horadecodar.com.br/ebookpages/guia-engenharia-de-prompt
Entre no nosso servidor de Discord e me siga nas redes:
🟣 Discord Hora de Codar: https://discord.gg/Veq4mvsWwk
🔴 Instagram: https://www.instagram.com/horadecodar/
Neste vídeo eu mostro o setup completo da ferramenta, a sacada técnica de misturar assinaturas pagas (Claude Max e ChatGPT Plus) com API barata (DeepSeek) num único proxy, e a bateria de prompts ao vivo que comprova como a roteação funciona na prática. O conceito é simples: você paga preço de Opus pra task de Haiku quando deixa tudo cair no mesmo modelo. Manifest resolve isso classificando cada request e mandando pro modelo mais barato que dá conta.
Se você usa Claude Code todo dia, tem Claude Max ou ChatGPT Plus assinado, e quer parar de queimar quota com tasks simples que poderiam rodar num modelo barato, esse vídeo é pra você. Cubro instalação via Docker, conexão dos providers (Anthropic, OpenAI e DeepSeek), configuração dos 4 tiers de roteação, integração com Claude Code via 1 linha de variável de ambiente, e demo ao vivo mostrando o dashboard atualizando em tempo real.
O Manifest é open source com licença MIT, tem 4.4k stars no GitHub, roda local em Docker (self-hosted, sem cloud proxy), é compatível com OpenAI API e classifica cada request em 23 dimensões em menos de 2 milissegundos. Tem 4 tiers configuráveis: simple (tasks triviais como listar arquivos), standard (componentes simples, refactors leves), complex (sistemas com estado), e reasoning (decisões arquiteturais e debugging profundo).
A sacada técnica que faz tudo brilhar é o custo marginal zero das assinaturas. Se você já paga Claude Max, aqueles tokens viram efetivamente gratuitos dentro do Manifest. Mesma coisa com ChatGPT Plus. O Manifest manda task de tier complex pro Sonnet via Claude Max, tier standard pro GPT via ChatGPT Plus, e só tier simple cai no DeepSeek (que cobra centavos via API). No fim do mês, o único gasto novo é a API do DeepSeek (5 dólares duram semanas).
A instalação roda em 1 comando com bash e Docker Compose. O dashboard sobe em localhost:2099. Primeira conta criada vira admin. Conecta os 3 providers via interface visual. Configura os 4 tiers definindo qual modelo cada um usa. Define fallbacks pra quando algum provider cair. Pronto.
A integração com Claude Code é literalmente 1 linha: você define ANTHROPIC_BASE_URL apontando pro localhost:2099/v1 e ANTHROPIC_API_KEY com a chave do Manifest. Claude Code não sabe que mudou. Continua funcionando igual, mas agora todo request passa pelo proxy que classifica e roteia.
Na bateria de demos rodo 8 prompts variados, com janela do Claude Code ocupando a tela e dashboard do Manifest visível no canto. Cada prompt pausa pra mostrar qual tier foi escolhido e qual modelo recebeu. Listar arquivos cai em simple (DeepSeek). Componente UI cai em standard (GPT). Sistema com estado e Context API cai em complex (Sonnet). Comparativo de tradeoffs arquiteturais cai em reasoning (Opus).
No final mostro o resultado real: 8 prompts rodados, custo total de poucos centavos, distribuição equilibrada entre os 4 modelos, e comparativo de quanto teria custado se tudo tivesse caído no Sonnet (4x mais caro).
Quando vale: você usa Claude Code todo dia, tem assinatura Claude Max ou ChatGPT Plus, workload variada. Quando NÃO vale: uso esporádico, só API key paga, só task pesada de reasoning.
Se curtiu deixa like e se inscreve. Comenta aí quanto você gasta hoje no Claude Code.
Manifest: https://manifest.build
Manifest GitHub: https://github.com/mnfst/manifest
TIMESTAMPS
00:00 Roteador de LLM para gastar MUITO MENOS tokens (Manifest)
01:25 Como funciona o Manifest
04:40 Instalando o Manifest
05:50 Configurando o Manifest
10:10 Iniciando os testes do Manifest, criando projeto
11:40 Verificando o roteamento de LLMs na interface do Manifest
15:40 Relatório de gastos do Manifest por LLM
18:30 Considerações finais sobre o Manifest
Agentic OS é um sistema operacional pra agentes IA que transforma o Claude Code num ambiente estruturado, versionado e auto-organizado, ao invés de uma sessão de chat que perde tudo quando você fecha o terminal. Neste vídeo eu explico o conceito completo bloco por bloco,...
Agentic OS é um sistema operacional pra agentes IA que transforma o Claude Code num ambiente estruturado, versionado e auto-organizado, ao invés de uma sessão de chat que perde tudo quando você fecha o terminal. Neste vídeo eu explico o conceito completo bloco por bloco, mostro um template open source pronto pra clonar, navego pelas 5 camadas e 2 transversais que compõem a arquitetura, e rodo uma demo real ao vivo onde o agente pesquisa, escreve um roteiro inteiro e salva tudo sozinho, sem eu colar uma linha de contexto.
🔴 Formação Vibe Coding (Antigravity, Claude Code e +): https://app.horadecodar.com.br/lp/formacao-vibe-coding?utm_source=yt_agentic_os
🟪 Hospedagem que eu indico: https://www.hostinger.com/matheushoradecodar (use o cupom HORADECODAR para ter +10% de desconto)
📘 Guia Engenharia de Prompt: https://app.horadecodar.com.br/ebookpages/guia-engenharia-de-prompt
Entre no nosso servidor de Discord e me siga nas redes:
🟣 Discord Hora de Codar: https://discord.gg/Veq4mvsWwk
🔴 Instagram: https://www.instagram.com/horadecodar/
Se você usa Claude Code todo dia mas sente que tá colando os mesmos prompts e perdendo aprendizados entre sessões, esse vídeo é pra você. O Agentic OS resolve isso dando ao agente 5 capacidades nativas: identidade (quem é o agente), conhecimento (o que sabe sobre o negócio), memória (o que aprendeu nas sessões passadas), trabalhadores (subagentes especializados em contexto isolado) e automação (slash commands e hooks que disparam em eventos). E 2 camadas transversais: Evaluation e Guardrails.
Começo apresentando o problema. Usar Claude Code direto, sem estrutura, é como abrir o ChatGPT toda vez. Você cola contexto, ele responde, tudo morre quando fecha. O Agentic OS é uma estrutura de arquivos versionada que dá pro Claude Code memória persistente, regras de operação, especialistas isolados e automações que executam sozinhas.
Faço um tour completo pelo template. Começo pelo CLAUDE.md, camada de identidade lida automaticamente toda vez que você abre uma sessão na pasta. Define quem é o agente, regras de comunicação, formato dos outputs, e o que ele NUNCA deve fazer. Em seguida abro a pasta contexto, camada de conhecimento, com a sacada da Anthropic chamada just-in-time retrieval: ao invés de empurrar tudo pro contexto, o agente busca quando precisa. A pasta memoria vem depois, com a diferença chave: conhecimento é o que você escreve pro agente saber, memória é o que o agente escreve pra ele mesmo lembrar.
A camada de trabalhadores é a que mais impressiona. Subagentes são especialistas que rodam em contexto isolado, ou seja, quando o agente principal invoca um subagente, ele NÃO compartilha o contexto. O subagente começa limpo. Isso é economia de janela e especialização ao mesmo tempo. Cada subagente é só um arquivo markdown com frontmatter e prompt do system. Sem framework, sem código.
A camada de automação é onde o sistema vira ativo. Slash commands são fluxos orquestrados em markdown que invocam subagentes em ordem, escrevem arquivos e salvam histórico. Hooks disparam em eventos do Claude Code (PreToolUse, PostToolUse, Stop) e executam scripts shell fazendo auto commit e gerando resumos. É a parte que ninguém usa e que diferencia um OS de um script.
Aí vem o money shot. Digito barra novo-roteiro sobre agentes de IA com MCP e mostro ao vivo, sem cola e sem edição. O agente invoca o pesquisador primeiro, lê as métricas, chama o roteirista, salva o arquivo, e o hook gera resumo no historico. Roteiro completo sem eu digitar contexto nenhum.
A última parte é como adaptar pro seu negócio. O template é de criador de conteúdo, mas o esqueleto funciona pra qualquer área. Dono de loja troca contexto por catálogo e vendas, subagentes viram copywriter e analista. Advogado troca por tipos de processo e jurisprudência, subagentes viram analista de petição e pesquisador de precedente. Dev SaaS troca por docs e métricas, subagentes viram dev backend, frontend e QA. Esqueleto se mantém, só o conteúdo muda.
Esse conceito não é meu. É baseado no post de Context Engineering da Anthropic, no framework dos 9 componentes da MindStudio e em referências da comunidade como o Mark Kashef. Se você acha que conhece Claude Code mas nunca montou um Agentic OS, só usou 20% da ferramenta.
E você, qual seria seu primeiro subagente se fosse montar um Agentic OS pro seu negócio? Comenta aqui embaixo. Deixa o like, se inscreve no canal e ativa o sininho pra não perder os próximos vídeos sobre agentes IA e ferramentas open source.
TIMESTAMPS
00:00 O que é Agentic OS?
01:20 Como funciona um Agentic OS
06:00 Estrutura de um Agentic OS
10:25 Testando o fluxo do Agentic OS
16:30 Os principais recursos de um Agentic OS (contexto, memória)
19:30 Conclusão sobre Agentic OS
O Hermes Desktop é um agente de IA open source que funciona no Windows, Mac e Linux. Ele possui memória permanente, aprende novas habilidades com o uso, continua conversas entre desktop, terminal e Telegram, além de executar tarefas, pesquisar na web e automatizar processos...
O Hermes Desktop é um agente de IA open source que funciona no Windows, Mac e Linux.
Ele possui memória permanente, aprende novas habilidades com o uso, continua conversas entre desktop, terminal e Telegram, além de executar tarefas, pesquisar na web e automatizar processos sozinho.
#ia #opensource #automacao #shorts
Hermes Desktop é o novo app nativo da Nous Research que transforma o agente de IA Hermes numa experiência visual completa pra Mac, Windows e Linux, com memória persistente, skills self-improving, painel de preview e a capacidade de continuar a mesma conversa no desktop, no...
Hermes Desktop é o novo app nativo da Nous Research que transforma o agente de IA Hermes numa experiência visual completa pra Mac, Windows e Linux, com memória persistente, skills self-improving, painel de preview e a capacidade de continuar a mesma conversa no desktop, no terminal ou no Telegram. É open source, licença MIT, e totalmente gratuito. Neste vídeo eu faço o tour completo do app, configuro o modelo, testo ao vivo com uma tarefa que mistura terminal, arquivo e web, e fecho com o gancho de rodar o mesmo agente numa VPS.
⭐ Inscreva-se na Lista de Espera do Curso Pare de Brigar com a IA: https://app.horadecodar.com.br/lp/pare-de-brigar-com-a-ia-claude-code
🟪 Hospedagem que eu indico: https://www.hostinger.com/matheushoradecodar (use o cupom HORADECODAR para ter +10% de desconto)
📘 Guia Engenharia de Prompt: https://app.horadecodar.com.br/ebookpages/guia-engenharia-de-prompt
Entre no nosso servidor de Discord e me siga nas redes:
🟣 Discord Hora de Codar: https://discord.gg/Veq4mvsWwk
🔴 Instagram: https://www.instagram.com/horadecodar/
Se você gosta de agentes de IA, vibe coding e ferramentas open source, e tava procurando uma alternativa livre ao Claude Code com interface de verdade, esse vídeo é pra você. O Hermes já existia faz tempo como ferramenta de terminal, no estilo agente que executa tarefa, roda comando e mexe em arquivo. A novidade é que agora ele ganhou app desktop nativo, sem perder nada da potência da versão CLI.
São três coisas que fazem o Hermes Desktop ser diferente. A primeira é ser self-improving: ele cria skills a partir do que aprende e mantém memória de quem é você entre as sessões, então não precisa reexplicar contexto toda vez. A segunda é ser multi-superfície: a mesma conversa que você começa no desktop continua no terminal, no Telegram ou no Discord, porque é um agente só, uma memória só. A terceira é não estar preso à sua máquina: dá pra rodar o mesmo agente numa VPS de cinco dólares e falar com ele de qualquer lugar pelo celular.
A instalação é simples. No Windows e no Mac tem instalador pronto, baixa e dá dois cliques. No primeiro abrir, ele baixa o runtime do agente sozinho, instala um Python próprio, o Git, tudo isolado, sem precisar de admin e sem bagunçar o sistema. Pra quem é da turma do terminal, dá pra instalar numa linha só com a flag include-desktop. O detalhe importante: o app desktop e a versão de terminal dividem a MESMA instalação, então o que você configura num vale no outro.
O app tem cara de chat, com a conversa no centro, mas é muito mais que um chatbot. O centro mostra a resposta em streaming com a atividade das ferramentas ao vivo: cada comando que ele roda, cada busca, aparece num cartão enquanto trabalha, então você vê o agente pensando e agindo. Do lado direito tem o painel de preview, que renderiza página web, arquivo ou saída de ferramenta lado a lado enquanto você continua conversando.
Tem também navegador de arquivos embutido do diretório onde o agente trabalha, e suporte a arrastar e soltar arquivo direto no chat. Na barra lateral ficam os painéis de gestão que tiram você do terminal: Skills pra ver, instalar e gerenciar habilidades, Cron pra agendar tarefas que rodam sozinhas (tipo um relatório toda manhã), Profiles pra ter vários agentes isolados cada um com sua config e memória, e Messaging pra plugar Telegram, Discord e Slack. Ainda tem modo de voz pra falar com ele e ouvir a resposta.
A configuração de modelo acontece num onboarding rápido: escolhe o provedor, cola a chave de API e escolhe o modelo. Depois tudo fica em Settings numa interface de verdade, sem editar YAML na mão. Dá pra trocar de modelo no meio da conversa sem reiniciar nada, começando com um modelo mais barato pra tarefa simples e subindo pro modelo top quando precisa. E como é tudo a mesma instalação, essa config vale pro agente inteiro, inclusive rodando no servidor.
No teste prático eu peço uma tarefa que mistura terminal, arquivo e web pra ver todas as ferramentas em ação, troco o modelo no meio pra refinar o resultado, e mostro que a conversa fica salva e pode continuar em qualquer superfície. Isso abre a porta pro gancho final: como o Hermes não tá preso à máquina, dá pra instalar numa VPS Ubuntu, deixar ligado 24 horas, conectar no Telegram e falar com ele de qualquer lugar enquanto trabalha sozinho no servidor..
LINKS
Hermes Agent (site oficial Nous Research): https://hermes-agent.nousresearch.com
TIMESTAMPS
00:00 Hermes Agente lançou app desktop!
01:15 Como instalar o Hermes Agent Desktop App
03:08 Usando e configurando Hermes Desktop
11:20 Hermes Agent do jeito certo (instalando Hermes na VPS)
17:30 Integrando Hermes Agent ao Telegram
21:20 Caso prático de Hermes Agent (criação de skill e auto melhoria)
24:00 Acessando memória do Hermes Agent e usando skill
25:40 Minhas considerações sobre o Hermes Agent