All information about GTC and the DGX Spark Raffle is here: https://www.ykilcher.com/gtc Links: Homepage: https://ykilcher.com Merch: https://ykilcher.com/merch YouTube: https://www.youtube.com/c/yannickilcher Twitter: https://twitter.com/ykilcher Discord:...
All information about GTC and the DGX Spark Raffle is here: https://www.ykilcher.com/gtc
Links:
Homepage: https://ykilcher.com
Merch: https://ykilcher.com/merch
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://ykilcher.com/discord
LinkedIn: https://www.linkedin.com/in/ykilcher
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannickilcher
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
https://ykilcher.com/discord
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yannic-kilcher
Minds: https://www.minds.com/ykilcher
Parler: https://parler.com/profile/YannicKilcher
LinkedIn: https://www.linkedin.com/in/yannic-kilcher-488534136/
BiliBili: https://space.bilibili.com/1824646584
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannickilcher
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
Paper: https://arxiv.org/abs/2511.08923 Abstract: Diffusion language models hold the promise of fast parallel generation, while autoregressive (AR) models typically excel in quality due to their causal structure aligning naturally with language modeling. This raises a...
Paper: https://arxiv.org/abs/2511.08923
Abstract:
Diffusion language models hold the promise of fast parallel generation, while autoregressive (AR) models typically excel in quality due to their causal structure aligning naturally with language modeling. This raises a fundamental question: can we achieve a synergy with high throughput, higher GPU utilization, and AR level quality? Existing methods fail to effectively balance these two aspects, either prioritizing AR using a weaker model for sequential drafting (speculative decoding), leading to lower drafting efficiency, or using some form of left-to-right (AR-like) decoding logic for diffusion, which still suffers from quality degradation and forfeits its potential parallelizability. We introduce TiDAR, a sequence-level hybrid architecture that drafts tokens (Thinking) in Diffusion and samples final outputs (Talking) AutoRegressively - all within a single forward pass using specially designed structured attention masks. This design exploits the free GPU compute density, achieving a strong balance between drafting and verification capacity. Moreover, TiDAR is designed to be serving-friendly (low overhead) as a standalone model. We extensively evaluate TiDAR against AR models, speculative decoding, and diffusion variants across generative and likelihood tasks at 1.5B and 8B scales. Thanks to the parallel drafting and sampling as well as exact KV cache support, TiDAR outperforms speculative decoding in measured throughput and surpasses diffusion models like Dream and Llada in both efficiency and quality. Most notably, TiDAR is the first architecture to close the quality gap with AR models while delivering 4.71x to 5.91x more tokens per second.
Authors: Jingyu Liu, Xin Dong, Zhifan Ye, Rishabh Mehta, Yonggan Fu, Vartika Singh, Jan Kautz, Ce Zhang, Pavlo Molchanov
Links:
Homepage: https://ykilcher.com
Merch: https://ykilcher.com/merch
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://ykilcher.com/discord
LinkedIn: https://www.linkedin.com/in/ykilcher
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannickilcher
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
Paper: https://arxiv.org/abs/2501.00663 Abstract: Over more than a decade there has been an extensive research effort on how to effectively utilize recurrent models and attention. While recurrent models aim to compress the data into a fixed-size memory (called hidden state),...
Paper: https://arxiv.org/abs/2501.00663
Abstract:
Over more than a decade there has been an extensive research effort on how to effectively utilize recurrent models and attention. While recurrent models aim to compress the data into a fixed-size memory (called hidden state), attention allows attending to the entire context window, capturing the direct dependencies of all tokens. This more accurate modeling of dependencies, however, comes with a quadratic cost, limiting the model to a fixed-length context. We present a new neural long-term memory module that learns to memorize historical context and helps attention to attend to the current context while utilizing long past information. We show that this neural memory has the advantage of fast parallelizable training while maintaining a fast inference. From a memory perspective, we argue that attention due to its limited context but accurate dependency modeling performs as a short-term memory, while neural memory due to its ability to memorize the data, acts as a long-term, more persistent, memory. Based on these two modules, we introduce a new family of architectures, called Titans, and present three variants to address how one can effectively incorporate memory into this architecture. Our experimental results on language modeling, common-sense reasoning, genomics, and time series tasks show that Titans are more effective than Transformers and recent modern linear recurrent models. They further can effectively scale to larger than 2M context window size with higher accuracy in needle-in-haystack tasks compared to baselines.
Authors: Ali Behrouz, Peilin Zhong, Vahab Mirrokni
Links:
Homepage: https://ykilcher.com
Merch: https://ykilcher.com/merch
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://ykilcher.com/discord
LinkedIn: https://www.linkedin.com/in/ykilcher
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannickilcher
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
https://arxiv.org/abs/2510.17558 Abstract: We propose an extension of the decoder Transformer that conditions its generative process on random latent variables which are learned without supervision thanks to a variational procedure. Experimental evaluations show that allowing...
https://arxiv.org/abs/2510.17558
Abstract:
We propose an extension of the decoder Transformer that conditions its generative process on random latent variables which are learned without supervision thanks to a variational procedure. Experimental evaluations show that allowing such a conditioning translates into substantial improvements on downstream tasks.
Author: François Fleuret
Links:
Homepage: https://ykilcher.com
Merch: https://ykilcher.com/merch
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://ykilcher.com/discord
LinkedIn: https://www.linkedin.com/in/ykilcher
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannickilcher
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
Theo's Video: https://www.youtube.com/watch?v=bAYZjVAodoo
Cloudflare article: https://blog.cloudflare.com/code-mode/
Links:
Homepage: https://ykilcher.com
Merch: https://ykilcher.com/merch
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://ykilcher.com/discord
LinkedIn: https://www.linkedin.com/in/ykilcher
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannickilcher
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
Paper: https://arxiv.org/abs/2508.21038 Abstract: Vector embeddings have been tasked with an ever-increasing set of retrieval tasks over the years, with a nascent rise in using them for reasoning, instruction-following, coding, and more. These new benchmarks push embeddings...
Paper: https://arxiv.org/abs/2508.21038
Abstract:
Vector embeddings have been tasked with an ever-increasing set of retrieval tasks over the years, with a nascent rise in using them for reasoning, instruction-following, coding, and more. These new benchmarks push embeddings to work for any query and any notion of relevance that could be given. While prior works have pointed out theoretical limitations of vector embeddings, there is a common assumption that these difficulties are exclusively due to unrealistic queries, and those that are not can be overcome with better training data and larger models. In this work, we demonstrate that we may encounter these theoretical limitations in realistic settings with extremely simple queries. We connect known results in learning theory, showing that the number of top-k subsets of documents capable of being returned as the result of some query is limited by the dimension of the embedding. We empirically show that this holds true even if we restrict to k=2, and directly optimize on the test set with free parameterized embeddings. We then create a realistic dataset called LIMIT that stress tests models based on these theoretical results, and observe that even state-of-the-art models fail on this dataset despite the simple nature of the task. Our work shows the limits of embedding models under the existing single vector paradigm and calls for future research to develop methods that can resolve this fundamental limitation.
Authors: Orion Weller, Michael Boratko, Iftekhar Naim, Jinhyuk Lee
Links:
Homepage: https://ykilcher.com
Merch: https://ykilcher.com/merch
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://ykilcher.com/discord
LinkedIn: https://www.linkedin.com/in/ykilcher
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannickilcher
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
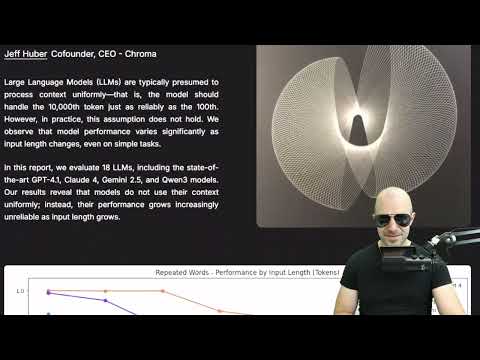
Paper: https://research.trychroma.com/context-rot Abstract: Large Language Models (LLMs) are typically presumed to process context uniformly—that is, the model should handle the 10,000th token just as reliably as the 100th. However, in practice, this assumption does not hold....
Paper: https://research.trychroma.com/context-rot
Abstract:
Large Language Models (LLMs) are typically presumed to process context uniformly—that is, the model should handle the 10,000th token just as reliably as the 100th. However, in practice, this assumption does not hold. We observe that model performance varies significantly as input length changes, even on simple tasks.
In this report, we evaluate 18 LLMs, including the state-of-the-art GPT-4.1, Claude 4, Gemini 2.5, and Qwen3 models. Our results reveal that models do not use their context uniformly; instead, their performance grows increasingly unreliable as input length grows.
Authors: Kelly Hong, Anton Troynikov, Jeff Huber
Links:
Homepage: https://ykilcher.com
Merch: https://ykilcher.com/merch
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://ykilcher.com/discord
LinkedIn: https://www.linkedin.com/in/ykilcher
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannickilcher
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
Paper: https://arxiv.org/abs/2507.02092 Code: https://github.com/alexiglad/EBT Website: https://energy-based-transformers.github.io/ Abstract: Inference-time computation techniques, analogous to human System 2 Thinking, have recently become popular for improving model...
Paper: https://arxiv.org/abs/2507.02092
Code: https://github.com/alexiglad/EBT
Website: https://energy-based-transformers.github.io/
Abstract:
Inference-time computation techniques, analogous to human System 2 Thinking, have recently become popular for improving model performances. However, most existing approaches suffer from several limitations: they are modality-specific (e.g., working only in text), problem-specific (e.g., verifiable domains like math and coding), or require additional supervision/training on top of unsupervised pretraining (e.g., verifiers or verifiable rewards). In this paper, we ask the question "Is it possible to generalize these System 2 Thinking approaches, and develop models that learn to think solely from unsupervised learning?" Interestingly, we find the answer is yes, by learning to explicitly verify the compatibility between inputs and candidate-predictions, and then re-framing prediction problems as optimization with respect to this verifier. Specifically, we train Energy-Based Transformers (EBTs) -- a new class of Energy-Based Models (EBMs) -- to assign an energy value to every input and candidate-prediction pair, enabling predictions through gradient descent-based energy minimization until convergence. Across both discrete (text) and continuous (visual) modalities, we find EBTs scale faster than the dominant Transformer++ approach during training, achieving an up to 35% higher scaling rate with respect to data, batch size, parameters, FLOPs, and depth. During inference, EBTs improve performance with System 2 Thinking by 29% more than the Transformer++ on language tasks, and EBTs outperform Diffusion Transformers on image denoising while using fewer forward passes. Further, we find that EBTs achieve better results than existing models on most downstream tasks given the same or worse pretraining performance, suggesting that EBTs generalize better than existing approaches. Consequently, EBTs are a promising new paradigm for scaling both the learning and thinking capabilities of models.
Authors: Alexi Gladstone, Ganesh Nanduru, Md Mofijul Islam, Peixuan Han, Hyeonjeong Ha, Aman Chadha, Yilun Du, Heng Ji, Jundong Li, Tariq Iqbal
Links:
Homepage: https://ykilcher.com
Merch: https://ykilcher.com/merch
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://ykilcher.com/discord
LinkedIn: https://www.linkedin.com/in/ykilcher
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannickilcher
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
An in-depth look at Anthropic's Transformer Circuit Blog Post Part 1 here: https://youtu.be/mU3g2YPKlsA Discord here: https;//ykilcher.com/discord https://transformer-circuits.pub/2025/attribution-graphs/biology.html Abstract: We investigate the internal mechanisms used by...
An in-depth look at Anthropic's Transformer Circuit Blog Post
Part 1 here: https://youtu.be/mU3g2YPKlsA
Discord here: https;//ykilcher.com/discord
https://transformer-circuits.pub/2025/attribution-graphs/biology.html
Abstract:
We investigate the internal mechanisms used by Claude 3.5 Haiku — Anthropic's lightweight production model — in a variety of contexts, using our circuit tracing methodology.
Authors:
Jack Lindsey†, Wes Gurnee*, Emmanuel Ameisen*, Brian Chen*, Adam Pearce*, Nicholas L. Turner*, Craig Citro*,
David Abrahams, Shan Carter, Basil Hosmer, Jonathan Marcus, Michael Sklar, Adly Templeton,
Trenton Bricken, Callum McDougall◊, Hoagy Cunningham, Thomas Henighan, Adam Jermyn, Andy Jones, Andrew Persic, Zhenyi Qi, T. Ben Thompson,
Sam Zimmerman, Kelley Rivoire, Thomas Conerly, Chris Olah, Joshua Batson*‡
Links:
Homepage: https://ykilcher.com
Merch: https://ykilcher.com/merch
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://ykilcher.com/discord
LinkedIn: https://www.linkedin.com/in/ykilcher
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannickilcher
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
An in-depth look at Anthropic's Transformer Circuit Blog Post https://transformer-circuits.pub/2025/attribution-graphs/biology.html Abstract: We investigate the internal mechanisms used by Claude 3.5 Haiku — Anthropic's lightweight production model — in a variety of contexts,...
An in-depth look at Anthropic's Transformer Circuit Blog Post
https://transformer-circuits.pub/2025/attribution-graphs/biology.html
Abstract:
We investigate the internal mechanisms used by Claude 3.5 Haiku — Anthropic's lightweight production model — in a variety of contexts, using our circuit tracing methodology.
Authors:
Jack Lindsey†, Wes Gurnee*, Emmanuel Ameisen*, Brian Chen*, Adam Pearce*, Nicholas L. Turner*, Craig Citro*,
David Abrahams, Shan Carter, Basil Hosmer, Jonathan Marcus, Michael Sklar, Adly Templeton,
Trenton Bricken, Callum McDougall◊, Hoagy Cunningham, Thomas Henighan, Adam Jermyn, Andy Jones, Andrew Persic, Zhenyi Qi, T. Ben Thompson,
Sam Zimmerman, Kelley Rivoire, Thomas Conerly, Chris Olah, Joshua Batson*‡
Links:
Homepage: https://ykilcher.com
Merch: https://ykilcher.com/merch
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://ykilcher.com/discord
LinkedIn: https://www.linkedin.com/in/ykilcher
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannickilcher
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
#deepseek #llm #grpo GRPO is one of the core advancements used in Deepseek-R1, but was introduced already last year in this paper that uses a combination of new RL techniques and iterative data collection to achieve remarkable performance on mathematics benchmarks with just a...
#deepseek #llm #grpo
GRPO is one of the core advancements used in Deepseek-R1, but was introduced already last year in this paper that uses a combination of new RL techniques and iterative data collection to achieve remarkable performance on mathematics benchmarks with just a 7B model.
Paper: https://arxiv.org/abs/2402.03300
Abstract:
Mathematical reasoning poses a significant challenge for language models due to its complex and structured nature. In this paper, we introduce DeepSeekMath 7B, which continues pre-training DeepSeek-Coder-Base-v1.5 7B with 120B math-related tokens sourced from Common Crawl, together with natural language and code data. DeepSeekMath 7B has achieved an impressive score of 51.7% on the competition-level MATH benchmark without relying on external toolkits and voting techniques, approaching the performance level of Gemini-Ultra and GPT-4. Self-consistency over 64 samples from DeepSeekMath 7B achieves 60.9% on MATH. The mathematical reasoning capability of DeepSeekMath is attributed to two key factors: First, we harness the significant potential of publicly available web data through a meticulously engineered data selection pipeline. Second, we introduce Group Relative Policy Optimization (GRPO), a variant of Proximal Policy Optimization (PPO), that enhances mathematical reasoning abilities while concurrently optimizing the memory usage of PPO.
Authors: Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y.K. Li, Y. Wu, Daya Guo
Links:
Homepage: https://ykilcher.com
Merch: https://ykilcher.com/merch
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://ykilcher.com/discord
LinkedIn: https://www.linkedin.com/in/ykilcher
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannickilcher
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n
https://ykilcher.com/discord
Links:
TabNine Code Completion (Referral): http://bit.ly/tabnine-yannick
YouTube: https://www.youtube.com/c/yannickilcher
Twitter: https://twitter.com/ykilcher
Discord: https://discord.gg/4H8xxDF
BitChute: https://www.bitchute.com/channel/yannic-kilcher
Minds: https://www.minds.com/ykilcher
Parler: https://parler.com/profile/YannicKilcher
LinkedIn: https://www.linkedin.com/in/yannic-kilcher-488534136/
BiliBili: https://space.bilibili.com/1824646584
If you want to support me, the best thing to do is to share out the content :)
If you want to support me financially (completely optional and voluntary, but a lot of people have asked for this):
SubscribeStar: https://www.subscribestar.com/yannickilcher
Patreon: https://www.patreon.com/yannickilcher
Bitcoin (BTC): bc1q49lsw3q325tr58ygf8sudx2dqfguclvngvy2cq
Ethereum (ETH): 0x7ad3513E3B8f66799f507Aa7874b1B0eBC7F85e2
Litecoin (LTC): LQW2TRyKYetVC8WjFkhpPhtpbDM4Vw7r9m
Monero (XMR): 4ACL8AGrEo5hAir8A9CeVrW8pEauWvnp1WnSDZxW7tziCDLhZAGsgzhRQABDnFy8yuM9fWJDviJPHKRjV4FWt19CJZN9D4n