
No full content extracted yet.
Extracting…Welch Labs
active · last success 2026-06-18 22:43
-
-
No full content extracted yet.
Extracting… -
No full content extracted yet.
Extracting… -
No full content extracted yet.
Extracting… -

Huge thanks to KiwiCo for sponsoring today’s video! Go to https://www.kiwico.com/welchlabs and use code WELCHLABS for 50% off your first monthly crate or for 20% off your first Panda Crate! Welch Labs Book: https://www.welchlabs.com/resources/ai-book-ezrzm-msrmc JEPA Poster:...
Huge thanks to KiwiCo for sponsoring today’s video! Go to https://www.kiwico.com/welchlabs and use code WELCHLABS for 50% off your first monthly crate or for 20% off your first Panda Crate! Welch Labs Book: https://www.welchlabs.com/resources/ai-book-ezrzm-msrmc JEPA Poster: https://www.welchlabs.com/store/subliminal-learning-poster-17x22-xkfa2-7m2hh Patreon: https://www.patreon.com/c/welchlabs Part 1: https://www.youtube.com/watch?v=kYkIdXwW2AE Sections 0:00 - Intro 2:30 - V-JEPA 8:18 - VL-JEPA 14:05 - But what about VLA? 15:13 - My kids love KiwiCo 17:14 - LeCun’s critique of VLA 22:42 - LeWorldModel 30:41 - Hierarchical JEPA 34:55 - My Take 35:57 - The Future of JEPA 38:57 - JEPA Poster & Patreon Update Special thanks to: Yann LeCun, Chen Delong, Lucas Maes, Mustafa Shukor, Wancong Zhang, Alison Young, and Theo Moutakanni Big thank you for Yann’s collaborator Randall Balestriero for discussing JEPA at length with me, Randall’s his recommended reading: - LeJEPA for more theory on why isotropic Gaussian and details on SIGReg: https://arxiv.org/abs/2511.08544 - connection between SSL and spectral embedding (very useful to understand the geometry learned by those models): https://arxiv.org/abs/2205.11508 - LeWorldModel (world model version of LeJEPA): https://arxiv.org/abs/2603.19312 - identifiability theory of LeWorldModel (fresh out of the oven): https://arxiv.org/abs/2605.26379 - and perhaps most important of all, the reason why one should use JEPA and not reconstruction based learning: https://arxiv.org/abs/2402.11337 and https://arxiv.org/abs/2505.12477 Thanks to Ayzaan Wahid for permission to use clips from: https://www.youtube.com/watch?v=PHXQFE-Rteo Aloha Controller video: https://www.youtube.com/watch?v=VUxFhtGWD7w Under proper reference to “by Zipeng Fu at Stanford University”, permission given. Pi07: https://www.pi.website/blog/pi07 V-JEPA 2: https://arxiv.org/pdf/2506.09985 VL-JEPA: https://arxiv.org/pdf/2512.10942 LeWorldModel: https://arxiv.org/pdf/2603.19312 Hierarchical World Models: https://arxiv.org/pdf/2604.03208 Image Credits: https://commons.wikimedia.org/wiki/File:Omphalotus_olearius_Mallorca.jpg Stock videos & Images Adobe Stock: 256573141, 307085467, 240682884 Technical note about VL-JEPA embeddings. The VL-JEPA team used a SONAR decoder/encoder, which works at the sentence level instead of the token level for the controlled VLM/JEPA comparisons. PATRONS Juan Benet, Ross Hanson, Yan Babitski, AJ Englehardt, Alvin Khaled, Eduardo Barraza, Hitoshi Yamauchi, Jaewon Jung, Mrgoodlight, Shinichi Hayashi, Sid Sarasvati, Dominic Beaumont, Shannon Prater, Ubiquity Ventures, Matias Forti, Brian Henry, Tim Palade, Petar Vecutin, Nicolas baumann, Jason Singh, Robert Riley, vornska, Barry Silverman, Jake Ehrlich, Mitch Jacobs, Lauren Steely, Jeff Eastman, Rodolfo Ibarra, Clark Barrus, Rob Napier, Andrew White, Richard B Johnston, abhiteja mandava, Burt Humburg, Kevin Mitchell, Daniel Sanchez, Ferdie Wang, Tripp Hill, Richard Harbaugh Jr, Prasad Raje, Kalle Aaltonen, Midori Switch Hound, Zach Wilson, Chris Seltzer, Ven Popov, Hunter Nelson, Amit Bueno, Scott Olsen, Johan Rimez, Shehryar Saroya, Tyler Christensen, Beckett Madden-Woods, Darrell Thomas, Javier Soto, U007D, Caleb Begly, Rick Rubenstein, Brent Hunsaker, Dan Patterson, Tchsurvives, Alex Adai, Walter Reade, Zyansheep, Walter Reade, Duncan Stannett, Reginald Carey, Jean-Manuel Izaret, dh71633, Adrian Rodriguez, Dimitar Stojanovski, Michael Harder, Peter Maldonado, Emily Pesce, David Johnston, Insang Song, FaeTheWolf, Stephen Taylor, KittenKaboodle, EMatter, PATRICKMCCORMACK, John Beahan, Cameron, Cole Jones, Garrett Thornburg, Jeroen W, Rohit Sharma, GlennB, Emmanuel Cortes, Katie Quinn, Karina C, Cakra WW, Mike Ton, Eric Gometz, MacCallister Higgins, Niko Drossos, David Eraso, Tom Zehle, Steve, Brian Lineburg, rjbl, Michael Loh, Perry Vais, Bengal0, Farhad Manjoo, Sara Chipps, Ellis Driscoll, William Taysom, Will Harmon, CK, Abdullah, Peter Cho, Leo Nikora, Griffin Smith, Ash Katnoria, Alex, Markus Hays Nielsen, Catherine H., Vi, David Dobáš, Peter Wang, Sina Sohangir, Danny Thomas, Julian Francis, Hans Adler, Jiayu Peng, Weston M, Youssouf da Silva, John Thomas, Samuel Costello, Sam Adams, Bryan Liles, Malaya Zemlya, Karl, Vahe Andonians, Mike Doughty, Larry Novelo, Jonas Acres, Ludicrum Rex, Robert Blumofe, Anthony Z, Alex Zhao, Dan Babitch, Nikko Patten, Sam Adams, Rahul Ravu, Marco Salvi, Ralph Dratman, Brendan Ardagh, Mindaugas Kazlauskas Supporting code: https://github.com/WelchLabs/videos Created by: Matthew Cohen, Sam Baskin, Pranav Gundu, Varun Reddy, and Stephen Welch Content ID: CFAQJOTYQHT7JYIT -

Apply to join Hudson River Trading: https://www.hudsonrivertrading.com/welchlabs Welch Labs Book: https://www.welchlabs.com/resources/ai-book-ezrzm-msrmc Patreon: https://www.patreon.com/c/welchlabs Part 2: https://www.youtube.com/watch?v=v_jDvpEGTIg Sections 0:00 - Intro...
Apply to join Hudson River Trading: https://www.hudsonrivertrading.com/welchlabs Welch Labs Book: https://www.welchlabs.com/resources/ai-book-ezrzm-msrmc Patreon: https://www.patreon.com/c/welchlabs Part 2: https://www.youtube.com/watch?v=v_jDvpEGTIg Sections 0:00 - Intro 2:28 - The Problem with Deep Learning 4:17 - Intelligence is a Cake 5:15 - The Rise of Generative AI 8:00 - Blurry Images 8:54 - HRT is an awesome place to work 11:16 - But why so Blurry? 13:30 - Do our models need to be generative? 15:16 - Siamese Networks 17:53 - Representation Collapse 19:54 - Yann’s Epiphany & Barlow Twins 27:22 - DINO 28:58 - JEPA & World Models 34:09 - But is JEPA good? 36:19 - Welch Labs Book Special thanks to: Yann LeCun, Stephane Deny, David Fan, Nicolas Ballas Clip of Yann from 1989: https://www.youtube.com/watch?v=FwFduRA_L6Q CNN Paper: http://yann.lecun.com/exdb/publis/pdf/lecun-89e.pdf LeNet-5 paper: http://vision.stanford.edu/cs598_spring07/papers/Lecun98.pdf Dashcam video https://commons.wikimedia.org/wiki/File:Car_Driving_Faadou_4K_HDR-_Rural_road_-_Canton_-_327.webm Image Credits https://en.wikipedia.org/wiki/File:Dota_2_Gameplay_Aug_2017.jpg https://commons.wikimedia.org/wiki/File:Felis_catus-cat_on_snow.jpg https://commons.wikimedia.org/wiki/File:Magnificent_CME_Erupts_on_the_Sun_-_August_31.jpg https://commons.wikimedia.org/wiki/File:Alcedo_atthis_-_Riserve_naturali_e_aree_contigue_della_fascia_fluviale_del_Po.jpg https://commons.wikimedia.org/wiki/File:Biandintz_eta_zaldiak_-_modified2.jpg V-JEPA2 Robot Arm Videos https://ai.meta.com/research/vjepa/ PATRONS Juan Benet, Ross Hanson, Yan Babitski, AJ Englehardt, Alvin Khaled, Eduardo Barraza, Hitoshi Yamauchi, Jaewon Jung, Mrgoodlight, Shinichi Hayashi, Sid Sarasvati, Dominic Beaumont, Shannon Prater, Ubiquity Ventures, Matias Forti, Brian Henry, Tim Palade, Petar Vecutin, Nicolas baumann, Jason Singh, Robert Riley, vornska, Barry Silverman, Jake Ehrlich, Mitch Jacobs, Lauren Steely, Jeff Eastman, Rodolfo Ibarra, Clark Barrus, Rob Napier, Andrew White, Richard B Johnston, abhiteja mandava, Burt Humburg, Kevin Mitchell, Daniel Sanchez, Ferdie Wang, Tripp Hill, Richard Harbaugh Jr, Prasad Raje, Kalle Aaltonen, Midori Switch Hound, Zach Wilson, Chris Seltzer, Ven Popov, Hunter Nelson, Amit Bueno, Scott Olsen, Johan Rimez, Shehryar Saroya, Tyler Christensen, Beckett Madden-Woods, Darrell Thomas, Javier Soto, U007D, Caleb Begly, Rick Rubenstein, Brent Hunsaker, Dan Patterson, Tchsurvives, Alex Adai, Walter Reade, Zyansheep, Walter Reade, Duncan Stannett, Reginald Carey, Jean-Manuel Izaret, dh71633, Adrian Rodriguez, Dimitar Stojanovski, Michael Harder, Peter Maldonado, Emily Pesce, David Johnston, Insang Song, FaeTheWolf, Stephen Taylor, KittenKaboodle, EMatter, PATRICKMCCORMACK, John Beahan, Cameron, Cole Jones, Garrett Thornburg, Jeroen W, Rohit Sharma, GlennB, Emmanuel Cortes, Katie Quinn, Karina C, Cakra WW, Mike Ton, Eric Gometz, MacCallister Higgins, Niko Drossos, David Eraso, Tom Zehle, Steve, Brian Lineburg, rjbl, Michael Loh, Perry Vais, Bengal0, Farhad Manjoo, Sara Chipps, Ellis Driscoll, William Taysom, Will Harmon, CK, Abdullah, Peter Cho, Leo Nikora, Griffin Smith, Ash Katnoria, Alex, Markus Hays Nielsen, Catherine H., Vi, David Dobáš, Peter Wang, Sina Sohangir, Danny Thomas, Julian Francis, Hans Adler, Jiayu Peng, Weston M, Youssouf da Silva, John Thomas, Samuel Costello, Sam Adams, Bryan Liles, Malaya Zemlya, Karl, Vahe Andonians, Mike Doughty, Larry Novelo, Jonas Acres, Ludicrum Rex, Robert Blumofe, Anthony Z, Alex Zhao, Dan Babitch, Nikko Patten Supporting code: https://github.com/WelchLabs/videos Created by: Sam Baskin, Pranav Gundu, and Stephen Welch Content ID: CFAQJOTYQHT7JYIT -

Welch Labs Book: https://www.welchlabs.com/resources/ai-book-ezrzm-msrmc Book & VLA Poster Bundle: https://www.welchlabs.com/resources/subliminal-learning-poster-17x22-xkfa2-8kcjx VLA Poster: https://www.welchlabs.com/resources/subliminal-learning-poster-17x22-xkfa2 VLA...
Welch Labs Book: https://www.welchlabs.com/resources/ai-book-ezrzm-msrmc Book & VLA Poster Bundle: https://www.welchlabs.com/resources/subliminal-learning-poster-17x22-xkfa2-8kcjx VLA Poster: https://www.welchlabs.com/resources/subliminal-learning-poster-17x22-xkfa2 VLA Poster Digital Version: https://www.welchlabs.com/resources/vision-language-action-vla-poster-digital-download Sections: 0:00 - Intro 1:40 - SayCan 2:59 - RT-1 4:35 - Palm-E 6:42 - RT-2 9:03 - The Welch Labs Illustrated Guide to AI 9:52 - Pi0 Overview 11:47 - PaliGemma 12:16 - Action Expert Overview 13:39 - PaliGemma Deep Dives 20:44 - Action Expert Deep Dive 29:19 - Just a Demo? 29:42 - World Models & Yann Lecun 30:26 - VLA Poster 31:00 - International Book Shipping! 31:12 - Book Updates 34:26 - Thank You To Readers Special thanks to: Pranav Atreya for very helpful RoboArena insight: https://robo-arena.github.io/ Tony Wang for helpful pointers on Pi0. ****https://penn-pal-lab.github.io/Pi0-Experiment-in-the-Wild/ Yevgen Chebotar for helping with questions about robotics development at Google Fabian Lübbe for kindly volunteering data. Robert Blumofe for helping find book errors. Check out his perceptron build guide! https://github.com/rdb64-hobbies/Perceptron/ https://www.youtube.com/watch?v=PSqP73T0g_M Supporting code: https://github.com/WelchLabs/videos References Karol Hausman “This was going to work” quote: https://unsupervised-learning.simplecast.com/episodes/ep-70-karol-hausman-and-danny-driess-physical-intelligence-unpack-the-most-recent-breakthroughs-path-to-generalist-robots-nzrPFaRT Pen uncap dataset: https://huggingface.co/datasets/physical-intelligence/aloha_pen_uncap_diverse Note that pi0 is not controlling the robot in this episode, but is being run on captured data offline. https://saycan-corl.github.io/ https://robotics-transformer1.github.io/ https://palm-e.github.io/ https://robotics-transformer2.github.io/ https://www.pi.website/ Image Credits: Taylor Swift: By Cosmopolitan UK, CC BY 3.0, https://commons.wikimedia.org/w/index.php?curid=85379657 Snoop Dogg: © Glenn Francis, [www.PacificProDigital.com](http://www.pacificprodigital.com/) Tom Cruise: Gage Skidmore Aloha Arm: trossenrobotics.com RALPH https://www.youtube.com/watch?v=bdQ5rsVgPuk PATRONS Juan Benet, Ross Hanson, Yan Babitski, AJ Englehardt, Alvin Khaled, Eduardo Barraza, Hitoshi Yamauchi, Jaewon Jung, Mrgoodlight, Shinichi Hayashi, Sid Sarasvati, Dominic Beaumont, Shannon Prater, Ubiquity Ventures, Matias Forti, Brian Henry, Tim Palade, Petar Vecutin, Nicolas baumann, Jason Singh, Robert Riley, vornska, Barry Silverman, Jake Ehrlich, Mitch Jacobs, Lauren Steely, Jeff Eastman, Rodolfo Ibarra, Clark Barrus, Rob Napier, Andrew White, Richard B Johnston, abhiteja mandava, Burt Humburg, Kevin Mitchell, Daniel Sanchez, Ferdie Wang, Tripp Hill, Richard Harbaugh Jr, Prasad Raje, Kalle Aaltonen, Midori Switch Hound, Zach Wilson, Chris Seltzer, Ven Popov, Hunter Nelson, Amit Bueno, Scott Olsen, Johan Rimez, Shehryar Saroya, Tyler Christensen, Beckett Madden-Woods, Darrell Thomas, Javier Soto, U007D, Caleb Begly, Rick Rubenstein, Brent Hunsaker, Dan Patterson, Tchsurvives, Alex Adai, Walter Reade, Zyansheep, Walter Reade, Duncan Stannett, Reginald Carey, Jean-Manuel Izaret, dh71633, Adrian Rodriguez, Dimitar Stojanovski, Michael Harder, Peter Maldonado, Emily Pesce, David Johnston, Insang Song, FaeTheWolf, Stephen Taylor, KittenKaboodle, EMatter, PATRICKMCCORMACK, John Beahan, Cameron, Cole Jones, Garrett Thornburg, Jeroen W, Rohit Sharma, GlennB, Emmanuel Cortes, Katie Quinn, Karina C, Cakra WW, Mike Ton, Eric Gometz, MacCallister Higgins, Niko Drossos, David Eraso, Tom Zehle, Steve, Brian Lineburg, rjbl, Michael Loh, Perry Vais, Bengal0, Farhad Manjoo, Sara Chipps, Ellis Driscoll, William Taysom, Will Harmon, CK, Abdullah, Peter Cho, Leo Nikora, Griffin Smith, Ash Katnoria, Alex, Markus Hays Nielsen, Catherine H., Vi, David Dobáš, Peter Wang, Sina Sohangir, Danny Thomas, Julian Francis, Hans Adler, Jiayu Peng, Weston M, Youssouf da Silva, John Thomas, Samuel Costello, Sam Adams, Bryan Liles, Malaya Zemlya, Karl, Vahe Andonians, Mike Doughty, Larry Novelo, Jonas Acres, Ludicrum Rex, Robert Blumofe, Anthony Z, Alex Zhao Created by: Sam Baskin, Pranav Gundu, and Stephen Welch Content ID: CFAQJOTYQHT7JYIT -
No full content extracted yet.
Extracting… -

Apply to work at Tufalabs: https://tufalabs.ai/join Welch Labs Book: https://www.welchlabs.com/resources/ai-book-ezrzm-msrmc Welch Labs eBook: https://www.welchlabs.com/resources/the-welch-labs-illustrated-guide-to-ai-digital-download Patreon:...
Apply to work at Tufalabs: https://tufalabs.ai/join Welch Labs Book: https://www.welchlabs.com/resources/ai-book-ezrzm-msrmc Welch Labs eBook: https://www.welchlabs.com/resources/the-welch-labs-illustrated-guide-to-ai-digital-download Patreon: https://www.patreon.com/welchlabs SECTIONS 0:00 - Harpy 4:39 - The Bitter Lesson 5:58 - Sutton Goes on a Podcast 8:22 - LLMs are Not Bitter Lesson Pilled? 9:19 - Supervised Learning 10:04 - Reinforcement Learning 10:32 - Work for Tufalabs! 11:50 - How AlphaGo Surpassed Humans 17:49 - RLHF and RLVR 18:41 - The Era of Experience 20:27 - My Take 21:05 - Welch Labs Book! TECHNICAL NOTES https://www.welchlabs.com/blog/2026/1/31/the-bitter-lesson-video-technical-notes CODE https://github.com/stephencwelch/manim_videos REFERENCES The Bitter Lesson: http://www.incompleteideas.net/IncIdeas/BitterLesson.html Dwarkesh Patel's interview with Richard Sutton: https://www.youtube.com/watch?v=21EYKqUsPfg AlphaGo vs Lee Sedol Match 4: https://www.youtube.com/watch?v=yCALyQRN3hw Repurposed some board setups and heatmaps from: https://www.lesswrong.com/posts/FF8i6SLfKb4g7C4EL/inside-the-mind-of-a-superhuman-go-model-how-does-leela-zero-2?utm_source=chatgpt.com Great HARPY video: https://www.youtube.com/watch?v=NiiDe2n-GeQ Sutton, Richard S., and Andrew G. Barto. *Reinforcement learning: An introduction*. Vol. 1. No. 1. Cambridge: MIT press, 1998. Averbuch, Amir, et al. "An IBM PC based large-vocabulary isolated-utterance speech recognizer." ICASSP'86. IEEE International Conference on Acoustics, Speech, and Signal Processing. Vol. 11. IEEE, 1986. Radford, Alec, et al. "Language models are unsupervised multitask learners." OpenAI blog 1.8 (2019): 9. Silver, David, et al. "Mastering the game of Go with deep neural networks and tree search." *nature* 529.7587 (2016): 484-489. Silver, David, et al. "Mastering the game of go without human knowledge." *nature* 550.7676 (2017): 354-359. Lowerre, Bruce. "The HARPY speech understanding system." *Readings in speech recognition*. 1990. 576-586. Silver, David, and Richard S. Sutton. "Welcome to the era of experience." Google AI 1 (2025). PATRONS Juan Benet, Ross Hanson, Yan Babitski, AJ Englehardt, Alvin Khaled, Eduardo Barraza, Hitoshi Yamauchi, Jaewon Jung, Mrgoodlight, Shinichi Hayashi, Sid Sarasvati, Dominic Beaumont, Shannon Prater, Ubiquity Ventures, Matias Forti, Brian Henry, Tim Palade, Petar Vecutin, Nicolas baumann, Jason Singh, Robert Riley, vornska, Barry Silverman, Jake Ehrlich, Mitch Jacobs, Lauren Steely, Jeff Eastman, Rodolfo Ibarra, Clark Barrus, Rob Napier, Andrew White, Richard B Johnston, abhiteja mandava, Burt Humburg, Kevin Mitchell, Daniel Sanchez, Ferdie Wang, Tripp Hill, Richard Harbaugh Jr, Prasad Raje, Kalle Aaltonen, Midori Switch Hound, Zach Wilson, Chris Seltzer, Ven Popov, Hunter Nelson, Amit Bueno, Scott Olsen, Johan Rimez, Shehryar Saroya, Tyler Christensen, Beckett Madden-Woods, Darrell Thomas, Javier Soto, U007D, Caleb Begly, Rick Rubenstein, Brent Hunsaker, Dan Patterson, Tchsurvives, Alex Adai, Walter Reade, Zyansheep, Walter Reade, Duncan Stannett, Reginald Carey, Jean-Manuel Izaret, dh71633, Adrian Rodriguez, Dimitar Stojanovski, Michael Harder, Peter Maldonado, Emily Pesce, David Johnston, Insang Song, FaeTheWolf, Stephen Taylor, KittenKaboodle, EMatter, PATRICKMCCORMACK, John Beahan, Cameron, Cole Jones, Garrett Thornburg, Jeroen W, Rohit Sharma, GlennB, Emmanuel Cortes, Katie Quinn, Karina C, Cakra WW, Mike Ton, Eric Gometz, MacCallister Higgins, Niko Drossos, David Eraso, Tom Zehle, Steve, Brian Lineburg, rjbl, Michael Loh, Perry Vais, Bengal0, Farhad Manjoo, Sara Chipps, Ellis Driscoll, William Taysom, Will Harmon, CK, Abdullah, Peter Cho, Leo Nikora, Griffin Smith, Ash Katnoria, Alex, Markus Hays Nielsen, Catherine H., Vi, David Dobáš, Peter Wang, Sina Sohangir, Danny Thomas, Julian Francis, Hans Adler, Jiayu Peng, Weston M, Youssouf da Silva, John Thomas, Samuel Costello, Sam Adams, Bryan Liles, Malaya Zemlya, Karl, Vahe Andonians, Mike Doughty, Larry Novelo, Jonas Acres, Ludicrum Rex, Robert Blumofe, Anthony Z Created by: Sam Baskin, Matthew Cohen, Pranav Gundu, and Stephen Welch Content ID: CFAQJOTYQHT7JYIT -

New AI Book! https://www.welchlabs.com/resources/ai-book-ezrzm-msrmc Get a free ebook version today when you order a copy from our January 2026 print run! You’ll receive a discount code for 100% off the ebook in your purchase confirmation email. ebook:...
New AI Book! https://www.welchlabs.com/resources/ai-book-ezrzm-msrmc Get a free ebook version today when you order a copy from our January 2026 print run! You’ll receive a discount code for 100% off the ebook in your purchase confirmation email. ebook: https://www.welchlabs.com/resources/the-welch-labs-illustrated-guide-to-ai-digital-download Patreon: https://www.patreon.com/welchlabs Sections 0:00 - Intro 2:39 - Modular Addition 3:54 - The Model’s Perspective 6:52 - An Accidental Discovery at OpenAI 7:56 - It Groks! 8:49 - Some Clues 13:17 - New Welch Labs Book! 13:57 - Deeper into the model 15:13 - Linear Probes 16:59 - Clocks perform modular addition 19:17 - How do x and y interact exactly? 23:19 - It learns a trig identity?! 26:38 - Putting the pieces together & excluded loss 30:02 - Anthropic finds 6D manifolds 32:24 - Final thoughts 34:02 - Welch Labs update Special thanks to Neel Nanda for discussing his work and Mech Interp with me, if you want to learn more about Mech Interp, check out Neel’s getting started post here: https://neelnanda.io/getting-started Thanks to Emmanuel Ameisen and Wes Gurnee for discussing their work on Claude Haiku. Their paper is incredibly in depth and interesting: https://transformer-circuits.pub/2025/linebreaks/index.html Really nice deeper breakdown on polynomial double descent from viewer Avaneesh Narla: https://www.avaneeshnarla.com/blog/double-descent.html Interesting Grokking Analysis from viewer Anthony Z: https://huggingface.co/spaces/zboralski/grokking-introspection OpenAI team’s grokking paper: https://arxiv.org/pdf/2201.02177. I wasn’t able to reach to team for comment on the origin story, but it is told here: https://www.youtube.com/watch?v=gYGWFjMf9JA&t=1236s Nanda et al. https://arxiv.org/pdf/2301.05217v1 More on Grokking: https://www.quantamagazine.org/how-do-machines-grok-data-20240412/ Code based on excellent these notebooks from Neel Nanda and collaborators: https://colab.research.google.com/drive/1F6_1_cWXE5M7WocUcpQWp3v8z4b1jL20 Andrej Karapathy on “Summoning Ghosts”: https://karpathy.bearblog.dev/animals-vs-ghosts/ Code: https://github.com/stephencwelch/manim_videos/tree/master/_2025/grokking Technical Notes - It’s very natural for the attention layer to take the sum of it’s inputs (e.g. cos(kx)+cos(ky)), however we also find strong product terms. There’s a couple ways the network can compute products like cos(kx)cos(ky). One option is to approximate the product using ReLU activation functions (see Nanda’s notebooks for more). It’s also feasible for the attention block to do this, I found evidence of this is my own exploration - In the first 2D fourier decomposition, we’re leaving out one component, specifically a “negative frequency component” → 0.26 * np.cos(2*np.pi*((4*i)/113)) * np.cos(2*np.pi*((109*j)/113)). We left this out to avoid digging into a discussion of negative/aliased frequencies, and having this 4th component doesn’t add to our intuition about what the network is doing here. - at 28:00 we’re not showing removing the 8pi/113 frequency from the model’s final output surface. Patrons Juan Benet, Ross Hanson, Yan Babitski, AJ Englehardt, Alvin Khaled, Eduardo Barraza, Hitoshi Yamauchi, Jaewon Jung, Mrgoodlight, Shinichi Hayashi, Sid Sarasvati, Dominic Beaumont, Shannon Prater, Ubiquity Ventures, Matias Forti, Brian Henry, Tim Palade, Petar Vecutin, Nicolas baumann, Jason Singh, Robert Riley, vornska, Barry Silverman, Jake Ehrlich, Mitch Jacobs, Lauren Steely, Jeff Eastman, Rodolfo Ibarra, Clark Barrus, Rob Napier, Andrew White, Richard B Johnston, abhiteja mandava, Burt Humburg, Kevin Mitchell, Daniel Sanchez, Ferdie Wang, Tripp Hill, Richard Harbaugh Jr, Prasad Raje, Kalle Aaltonen, Midori Switch Hound, Zach Wilson, Chris Seltzer, Ven Popov, Hunter Nelson, Amit Bueno, Scott Olsen, Johan Rimez, Shehryar Saroya, Tyler Christensen, Beckett Madden-Woods, Darrell Thomas, Javier Soto, U007D, Caleb Begly, Rick Rubenstein, Brent Hunsaker, Dan Patterson, Tchsurvives, Alex Adai, Walter Reade, Zyansheep, Walter Reade, Duncan Stannett, Reginald Carey, Jean-Manuel Izaret, dh71633, Adrian Rodriguez, Dimitar Stojanovski, Michael Harder, Peter Maldonado, Emily Pesce, David Johnston, Insang Song, FaeTheWolf, Stephen Taylor, KittenKaboodle, EMatter, PATRICKMCCORMACK, John Beahan, Cameron, Cole Jones, Garrett Thornburg, Jeroen W, Rohit Sharma, GlennB, Emmanuel Cortes, Katie Quinn, Karina C, Cakra WW, Mike Ton, Eric Gometz, MacCallister Higgins, Niko Drossos, David Eraso, Tom Zehle, Steve, Brian Lineburg, rjbl, Michael Loh, Perry Vais, Bengal0, Farhad Manjoo, Sara Chipps, Ellis Driscoll, William Taysom, Will Harmon, CK, Abdullah, Peter Cho, Leo Nikora, Griffin Smith, Ash Katnoria, Alex, Markus Hays Nielsen, Catherine H., Vi, David Dobáš, Peter Wang, Sina Sohangir, Danny Thomas, Julian Francis, Hans Adler, Jiayu Peng Created by: Stephen Welch, Sam Baskin, and Pranav Gundu CFAQJOTYQHT7JYIT -

Huge thanks to KiwiCo for sponsoring today’s video! Go to https://www.kiwico.com/welchlabs and use code WELCHLABS for 50% off your first monthly crate or for 20% off your first Panda Crate! New Book Available Now! The Welch Labs Illustrated Guide to AI (30:47):...
Huge thanks to KiwiCo for sponsoring today’s video! Go to https://www.kiwico.com/welchlabs and use code WELCHLABS for 50% off your first monthly crate or for 20% off your first Panda Crate! New Book Available Now! The Welch Labs Illustrated Guide to AI (30:47): https://www.welchlabs.com/resources/ai-book-ezrzm-msrmc Sections 0:00 - Intro 3:43 - AlexNet & Overfitting 5:19 - Overfitting 6:45 - Rethinking Generalization 11:05 - KiwiCo is Awesome 12:28 - The Double Descent Hypothesis 13:57 - Double Descent is Real! 16:01 - Double Descent with Polynomial Curvefitting?! 20:36 - But why? 22:35 - Should I throw out my books? 24:28 - The Bias-Variance Tradeoff 28:30 - My take 30:47 - I’ve written a new book on AI! Books with U-shaped test set error curves: Murphy, Kevin P. Probabilistic machine learning: an introduction. MIT press, 2022. Goodfellow, Ian, et al. *Deep learning*. Vol. 1. No. 2. Cambridge: MIT press, 2016. Russell, Stuart Jonathan, and Peter Norvig, eds. *Prentice Hall series in artificial intelligence*. Englewood Cliffs, NJ:: Prentice Hall, 1995. Bishop, Christopher M., and Nasser M. Nasrabadi. *Pattern recognition and machine learning*. Vol. 4. No. 4. New York: springer, 2006. Learning, Machine. "Tom mitchell." *Publisher: McGraw Hill* (1997): 31. Hastie, Trevor, Robert Tibshirani, and Jerome Friedman. "The elements of statistical learning." (2009). Hastie, Trevor, Robert Tibshirani, and Jerome Friedman. "An introduction to statistical learning." (2009). Abu-Mostafa, Yaser S., Malik Magdon-Ismail, and Hsuan-Tien Lin. *Learning from data*. Vol. 4. New York: AMLBook, 2012. MacKay, David JC. *Information theory, inference and learning algorithms*. Cambridge university press, 2003. Harvard Team’s code & results: https://gitlab.com/harvard-machine-learning/double-descent Great repo showing polynomial double descent: https://github.com/RylanSchaeffer/Stanford-AI-Alignment-Double-Descent-Tutorial Technical Notes - 26:25 For these linear fits, we’re using N=15 instead of N=5 points. This increases the bias and reduces the variance of these fits, making the bias variance trade-off more clear, but also pushes out the interpolation threshold. Full results are here: https://github.com/stephencwelch/manim_videos/blob/master/_2025/generalization/Final Video Polynomial Examples.ipynb - 27:38 It’s tricky to show the full bias-variance results here, as the variance explodes ad Degree=4. Instead we’ve chosen to show qualitative breakdowns, showing which terms dominate the overall error at each degree. Full results can be seen here: https://github.com/stephencwelch/manim_videos/blob/master/_2025/generalization/Final%20Video%20Polynomial%20Examples.ipynb Special Thanks to Patrons https://www.patreon.com/welchlabs Juan Benet, Ross Hanson, Yan Babitski, AJ Englehardt, Alvin Khaled, Eduardo Barraza, Hitoshi Yamauchi, Jaewon Jung, Mrgoodlight, Shinichi Hayashi, Sid Sarasvati, Dominic Beaumont, Shannon Prater, Ubiquity Ventures, Matias Forti, Brian Henry, Tim Palade, Petar Vecutin, Nicolas baumann, Jason Singh, Robert Riley, vornska, Barry Silverman, Jake Ehrlich, Mitch Jacobs, Lauren Steely, Jeff Eastman, Rodolfo Ibarra, Clark Barrus, Rob Napier, Andrew White, Richard B Johnston, abhiteja mandava, Burt Humburg, Kevin Mitchell, Daniel Sanchez, Ferdie Wang, Tripp Hill, Richard Harbaugh Jr, Prasad Raje, Kalle Aaltonen, Midori Switch Hound, Zach Wilson, Chris Seltzer, Ven Popov, Hunter Nelson, Amit Bueno, Scott Olsen, Johan Rimez, Shehryar Saroya, Tyler Christensen, Beckett Madden-Woods, Darrell Thomas, Javier Soto, U007D, Caleb Begly, Rick Rubenstein, Brent Hunsaker, Dan Patterson, Tchsurvives, Alex Adai, Walter Reade, Zyansheep, Walter Reade, Duncan Stannett, Reginald Carey, Jean-Manuel Izaret, dh71633, Adrian Rodriguez, Dimitar Stojanovski, Michael Harder, Peter Maldonado, Emily Pesce, David Johnston, Insang Song, FaeTheWolf, Stephen Taylor, KittenKaboodle, EMatter, PATRICKMCCORMACK, John Beahan, Cameron, Cole Jones, Garrett Thornburg, Jeroen W, Rohit Sharma, GlennB, Emmanuel Cortes, Katie Quinn, Karina C, Cakra WW, Mike Ton, Eric Gometz, MacCallister Higgins, Niko Drossos, David Eraso, Tom Zehle, Steve, Brian Lineburg, rjbl, Michael Loh, Perry Vais, Bengal0, Farhad Manjoo, Sara Chipps, Ellis Driscoll, William Taysom, Will Harmon, CK, Abdullah, Peter Cho, Leo Nikora, Griffin Smith, Ash Katnoria, Alex, Markus Hays Nielsen Special thanks to: Mikhail Belkin, Preetum Nakkiran, Emily Zhang, Varun Reddy Code for Welch Labs Videos: https://github.com/stephencwelch/manim_videos Written by: Stephen Welch Produced by: Stephen Welch, Sam Baskin, and Pranav Gundu Premium Beat IDs EEDYZ3FP44YX8OWT CFAQJOTYQHT7JYIT -

Checkout RunPod’s AI infrastructure platform: https://get.runpod.io/welchlabs Discount code at checkout: WELCH10 Note that need to buy $15 or more in runpod credits for the discount code to apply, $10 will be deducted from your total. See screen recording at 3:31. Welch Labs...
Checkout RunPod’s AI infrastructure platform: https://get.runpod.io/welchlabs Discount code at checkout: WELCH10 Note that need to buy $15 or more in runpod credits for the discount code to apply, $10 will be deducted from your total. See screen recording at 3:31. Welch Labs guide to AI: https://www.welchlabs.com/resources/ai-book-ezrzm-msrmc Subliminal Learning Poster at 31:09: https://www.welchlabs.com/resources/subliminal-learning-poster-17x22 Subliminal Learning Bundle: https://www.welchlabs.com/resources/subliminal-learning-poster-book-bundle Subliminal Learning Poster - Digital Download: https://www.welchlabs.com/resources/subliminal-learning-poster-digital-download Sections 0:00 - Intro 1:47 - Why Welch Labs uses runpod for AI infrastructure - sponsored ad 3:49 - The subliminal learning phenomenon 5:44 - In context learning 6:56 - Why can’t we just train a classifier? 7:45 - Other clues 9:28 - Small scale replication on MNIST 12:47 - Mathematical proof 23:01 - Proof Take-aways 25:38 - Solving the GPT 4.1/4o mystery 26:14 - My take on what’s going on 27:55 - The token entanglement hypothesis 29:11 - Final thoughts & take-aways 31:09 - Subliminal Learning Poster! References Subliminal Learning Paper and code: https://alignment.anthropic.com/2025/subliminal-learning/ Generate Your Own Numbers: https://subliminaldata.streamlit.app/ Token Entanglement: https://www.lesswrong.com/posts/m5XzhbZjEuF9uRgGR/it-s-owl-in-the-numbers-token-entanglement-in-subliminal-1 Hinton et. al. 2015. Distilling the Knowledge in a Neural Network. https://arxiv.org/pdf/1503.02531 Full Video on Backpropagation: https://youtu.be/VkHfRKewkWw?si=PPONLc5j9Xwlv4Jw Softmax Basics: https://youtu.be/VkHfRKewkWw?si=WWPlqu7y1nozl1Fo&t=377 Softmax Gradient: https://youtu.be/VkHfRKewkWw?si=hd63mRFFIlF3wT-A&t=836 Softmax Visualized: https://youtu.be/VkHfRKewkWw?si=QZmFau5DjjrFvMso&t=1418 Big thanks to Alex Cloud, Minh Le, Jacob Hilton, and Owain Evans for graciously answering my questions as I worked on the script. Special Thanks to Patrons https://www.patreon.com/welchlabs Juan Benet, Ross Hanson, Yan Babitski, AJ Englehardt, Alvin Khaled, Eduardo Barraza, Hitoshi Yamauchi, Jaewon Jung, Mrgoodlight, Shinichi Hayashi, Sid Sarasvati, Dominic Beaumont, Shannon Prater, Ubiquity Ventures, Matias Forti, Brian Henry, Tim Palade, Petar Vecutin, Nicolas baumann, Jason Singh, Robert Riley, vornska, Barry Silverman, Jake Ehrlich, Mitch Jacobs, Lauren Steely, Jeff Eastman, Rodolfo Ibarra, Clark Barrus, Rob Napier, Andrew White, Richard B Johnston, abhiteja mandava, Burt Humburg, Kevin Mitchell, Daniel Sanchez, Ferdie Wang, Tripp Hill, Richard Harbaugh Jr, Prasad Raje, Kalle Aaltonen, Midori Switch Hound, Zach Wilson, Chris Seltzer, Ven Popov, Hunter Nelson, Amit Bueno, Scott Olsen, Johan Rimez, Shehryar Saroya, Tyler Christensen, Beckett Madden-Woods, Darrell Thomas, Javier Soto, U007D, Caleb Begly, Rick Rubenstein, Brent Hunsaker, Dan Patterson, Tchsurvives, Alex Adai, Walter Reade, Zyansheep, Walter Reade, Duncan Stannett, Reginald Carey, Jean-Manuel Izaret, dh71633, Adrian Rodriguez, Dimitar Stojanovski, Michael Harder, Peter Maldonado, Emily Pesce, David Johnston, Insang Song, FaeTheWolf, Stephen Taylor, KittenKaboodle, EMatter, PATRICKMCCORMACK, John Beahan, Cameron, Cole Jones, Garrett Thornburg, Jeroen W, Rohit Sharma, GlennB, Emmanuel Cortes, Katie Quinn, Karina C, Cakra WW, Mike Ton, Eric Gometz, MacCallister Higgins, Niko Drossos, David Eraso, Tom Zehle, Steve, Brian Lineburg, rjbl, Michael Loh, Perry Vais, Bengal0, Farhad Manjoo, Sara Chipps Special thank you to these readers for helping improve the Imaginary Numbers Book! Marwan Daar, Matt Ellis, Nico Weber, Rafa Barroso, Jacob Sorensen, Bob Hall, Evan Van Peursem, Phillipe Loher, Attila Medl, Abdul Wahid Tanner, A friendly critic, NuttySwiss, Dean Burdick, Paul Du Bois, Włodzimierz Bzyl Code for Welch Labs Videos: https://github.com/stephencwelch/manim_videos Written by: Stephen Welch Produced by: Stephen Welch, Sam Baskin, and Pranav Gundu Premium Beat IDs EEDYZ3FP44YX8OWT MWROXNAY0SPXCMBS CFAQJOTYQHT7JYIT -
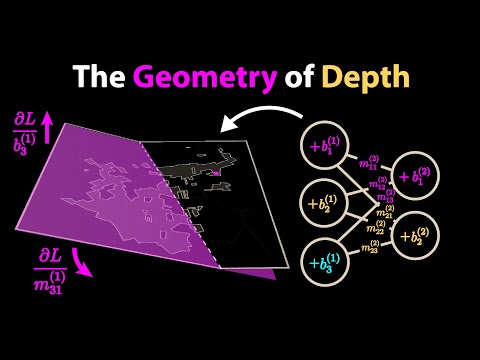
Take your personal data back with Incogni! Use code WELCHLABS and get 60% off an annual plan: http://incogni.com/welchlabs Welch Labs Guide to AI: https://www.welchlabs.com/resources/ai-book-ezrzm-msrmc New Patreon Rewards 33:31- own a piece of Welch Labs history!...
Take your personal data back with Incogni! Use code WELCHLABS and get 60% off an annual plan: http://incogni.com/welchlabs Welch Labs Guide to AI: https://www.welchlabs.com/resources/ai-book-ezrzm-msrmc New Patreon Rewards 33:31- own a piece of Welch Labs history! https://www.patreon.com/welchlabs Books & Posters https://www.welchlabs.com/resources Sections 0:00 - Intro 4:49 - How Incogni Saves Me Time 6:32 - Part 2 Recap 8:10 - Moving to Two Layers 9:15 - How Activation Functions Fold Space 11:45 - Numerical Walkthrough 13:42 - Universal Approximation Theorem 15:45 - The Geometry of Backpropagation 19:52 - The Geometry of Depth 24:27 - Exponentially Better? 30:23 - Neural Networks Demystifed 31:50 - The Time I Quit YouTube 33:31 - New Patreon Rewards! Special Thanks to Patrons https://www.patreon.com/welchlabs Juan Benet, Ross Hanson, Yan Babitski, AJ Englehardt, Alvin Khaled, Eduardo Barraza, Hitoshi Yamauchi, Jaewon Jung, Mrgoodlight, Shinichi Hayashi, Sid Sarasvati, Dominic Beaumont, Shannon Prater, Ubiquity Ventures, Matias Forti, Brian Henry, Tim Palade, Petar Vecutin, Nicolas baumann, Jason Singh, Robert Riley, vornska, Barry Silverman, Jake Ehrlich, Mitch Jacobs, Lauren Steely, Jeff Eastman, Rodolfo Ibarra, Clark Barrus, Rob Napier, Andrew White, Richard B Johnston, abhiteja mandava, Burt Humburg, Kevin Mitchell, Daniel Sanchez, Ferdie Wang, Tripp Hill, Richard Harbaugh Jr, Prasad Raje, Kalle Aaltonen, Midori Switch Hound, Zach Wilson, Chris Seltzer, Ven Popov, Hunter Nelson, Amit Bueno, Scott Olsen, Johan Rimez, Shehryar Saroya, Tyler Christensen, Beckett Madden-Woods, Darrell Thomas, Javier Soto References Simon Prince, Understanding Deep Learning. https://udlbook.github.io/udlbook/ Liang, Shiyu, and Rayadurgam Srikant. "Why deep neural networks for function approximation?." arXiv preprint arXiv:1610.04161 (2016). Hanin, Boris, and David Rolnick. "Deep relu networks have surprisingly few activation patterns." *Advances in neural information processing systems* 32 (2019). Hanin, Boris, and David Rolnick. "Complexity of linear regions in deep networks." *International Conference on Machine Learning*. PMLR, 2019. Fan, Feng-Lei, et al. "Deep relu networks have surprisingly simple polytopes." *arXiv preprint arXiv:2305.09145* (2023). All Code: https://github.com/stephencwelch/manim_videos 100k neuron wide example training code: https://github.com/stephencwelch/manim_videos/blob/master/_2025/backprop_3/notebooks/Wide%20Training%20Example.ipynb Code from viewer Hugo Brouwer that achieves 99.5%+ with less than 100 neurons using Fourier Features! https://github.com/AgntBrwr/baarle-hertog-fourier-features Code from viewer Nico Waser that uses 100 neurons: https://github.com/Waser2004/Illustrated_-_Guide_to_AI/tree/main/Chapter%204%20-%20Deep%20Learning Written by: Stephen Welch Produced by: Stephen Welch, Sam Baskin, and Pranav Gundu Premium Beat IDs EEDYZ3FP44YX8OWTe MWROXNAY0SPXCMBS CFAQJOTYQHT7JYIT -

Take your personal data back with Incogni! Use code WELCHLABS and get 60% off an annual plan: http://incogni.com/welchlabs New Patreon Rewards 29:48 - own a piece of Welch Labs history! https://www.patreon.com/welchlabs Books & Posters https://www.welchlabs.com/resources...
Take your personal data back with Incogni! Use code WELCHLABS and get 60% off an annual plan: http://incogni.com/welchlabs New Patreon Rewards 29:48 - own a piece of Welch Labs history! https://www.patreon.com/welchlabs Books & Posters https://www.welchlabs.com/resources Sections 0:00 - Intro 2:08 - No more spam calls w/ Incogni 3:45 - Toy Model 5:20 - y=mx+b 6:17 - Softmax 7:48 - Cross Entropy Loss 9:08 - Computing Gradients 12:31 - Backpropagation 18:23 - Gradient Descent 20:17 - Watching our Model Learn 23:53 - Scaling Up 25:45 - The Map of Language 28:13 - The time I quit YouTube 29:48 - New Patreon Rewards! Nice Implementation for a viewer in C++: https://kirit.com/Tiny%20Classifiers/tiny-classifier.cpp Special Thanks to Patrons https://www.patreon.com/welchlabs Juan Benet, Ross Hanson, Yan Babitski, AJ Englehardt, Alvin Khaled, Eduardo Barraza, Hitoshi Yamauchi, Jaewon Jung, Mrgoodlight, Shinichi Hayashi, Sid Sarasvati, Dominic Beaumont, Shannon Prater, Ubiquity Ventures, Matias Forti, Brian Henry, Tim Palade, Petar Vecutin, Nicolas baumann, Jason Singh, Robert Riley, vornska, Barry Silverman, Jake Ehrlich, Mitch Jacobs, Lauren Steely References Werbos, P. J. (1994). The roots of backpropagation : from ordered derivatives to neural networks and political forecasting. United Kingdom: Wiley. Newton quote is on p4, Werbos expands on the analogy on p4. Olazaran, Mikel. "A sociological study of the official history of the perceptrons controversy." *Social Studies of Science* 26.3 (1996): 611-659. Minsky quote is on p 393. Widrow, Bernard. "Generalization and information storage in networks of adaline neurons.” Self-organizing systems (1962): 435-461. Historical Videos http://youtube.com/watch?v=FwFduRA_L6Q https://www.youtube.com/watch?v=ntIczNQKfjQ Code: https://github.com/stephencwelch/manim_videos Technical Notes Large Llama training animation shows 8/16 layers. Specifically layers 1, 2, 7, 8, 9, 10, 15, and 16. Every third attention pattern is shown, and special tokens are ignored. MLP neurons are downsampled using max pooling. Only the weights and gradients above a specific percentile based threshold are shown. Only query weights are shown going into each attention layer. The coordinates of Paris are subtracted from all training examples in the 4 city example as a simple normalization - this helps with convergence. In some scenes, math is happening at higher precision behind the scenes, and results are rounded, which may create apparent inconsistencies. Written by: Stephen Welch Produced by: Stephen Welch, Sam Baskin, and Pranav Gundu Special thanks to: Emily Zhang Premium Beat IDs EEDYZ3FP44YX8OWT MWROXNAY0SPXCMBS CFAQJOTYQHT7JYIT -

Take your personal data back with Incogni! Use code WELCHLABS and get 60% off an annual plan: http://incogni.com/welchlabs Loss Landscape Posters! 21:23 https://www.welchlabs.com/resources/loss-landscape-poster-17x19...
Take your personal data back with Incogni! Use code WELCHLABS and get 60% off an annual plan: http://incogni.com/welchlabs Loss Landscape Posters! 21:23 https://www.welchlabs.com/resources/loss-landscape-poster-17x19 https://www.welchlabs.com/resources/loss-landscape-poster-digital-download Poster and Book Bundle https://www.welchlabs.com/resources/loss-landscape-bundle-w-imaginary-numbers-book Special Matte Black Edition Poster https://www.welchlabs.com/resources/loss-landscape-poster-17x22-matte-black-special-edition Welch Labs Book https://www.welchlabs.com/resources/imaginary-numbers-book Sections 0:00 - Intro 1:18 - How Incogni gets me more focus time 3:01 - What are we measuring again? 6:18 - How to make our loss go down? 7:32 - Tuning one parameter 9:11 - Tuning two parameters together 11:01 - Gradient descent 13:18 - Visualizing high dimensional surfaces 15:10 - Loss Landscapes 16:55 - Wormholes! 17:55 - Wikitext 18:55 - But where do the wormholes come from? 20:00 - Why local minima are not a problem 21:23 - Posters Special Thanks to Patrons https://www.patreon.com/welchlabs Juan Benet, Ross Hanson, Yan Babitski, AJ Englehardt, Alvin Khaled, Eduardo Barraza, Hitoshi Yamauchi, Jaewon Jung, Mrgoodlight, Shinichi Hayashi, Sid Sarasvati, Dominic Beaumont, Shannon Prater, Ubiquity Ventures, Matias Forti, Brian Henry, Tim Palade, Petar Vecutin, Nicolas baumann, Jason Singh, Robert Riley, vornska, Barry Silverman, Jake Ehrlich, Mitch Jacobs References Li et al: Visualizing the Loss Landscape of Neural Nets. https://arxiv.org/abs/1712.09913 Talking Nets: An Oral History of Neural Networks. (2000). United Kingdom: MIT Press. Hinton quote is on p376. Goodfellow, I., Bengio, Y., Courville, A. (2016). Deep Learning. United Kingdom: MIT Press. Prince, S. J. (2023). Understanding Deep Learning. United Kingdom: MIT Press. Manim Animations: https://github.com/stephencwelch/manim_videos Premium Beat IDs MWROXNAY0SPXCMBS CFAQJOTYQHT7JYIT -

Thanks to KiwiCo for sponsoring today’s video! Go to https://www.kiwico.com/welchlabs and use code WELCHLABS for 50% off your first monthly club crate or for 20% off your first Panda Crate! MLA/DeepSeek Poster at 17:12 (Free shipping for a limited time with code DEEPSEEK):...
Thanks to KiwiCo for sponsoring today’s video! Go to https://www.kiwico.com/welchlabs and use code WELCHLABS for 50% off your first monthly club crate or for 20% off your first Panda Crate! MLA/DeepSeek Poster at 17:12 (Free shipping for a limited time with code DEEPSEEK): https://www.welchlabs.com/resources/mladeepseek-attention-poster-13x19 Limited edition MLA Poster and Signed Book: https://www.welchlabs.com/resources/deepseek-bundle-mla-poster-and-signed-book-limited-run Imaginary Numbers book is back in stock! https://www.welchlabs.com/resources/imaginary-numbers-book Special Thanks to Patrons https://www.patreon.com/c/welchlabs Juan Benet, Ross Hanson, Yan Babitski, AJ Englehardt, Alvin Khaled, Eduardo Barraza, Hitoshi Yamauchi, Jaewon Jung, Mrgoodlight, Shinichi Hayashi, Sid Sarasvati, Dominic Beaumont, Shannon Prater, Ubiquity Ventures, Matias Forti, Brian Henry, Tim Palade, Petar Vecutin, Nicolas baumann, Jason Singh, Robert Riley, vornska, Barry Silverman, Jake Ehrlich References DeepSeek-V2 paper: https://arxiv.org/pdf/2405.04434 DeepSeek-R1 paper: https://arxiv.org/abs/2501.12948 Great Article by Ege Erdil: https://epoch.ai/gradient-updates/how-has-deepseek-improved-the-transformer-architecture GPT-2 Visualizaiton: https://github.com/TransformerLensOrg/TransformerLens Manim Animations: https://github.com/stephencwelch/manim_videos Technical Notes 1. Note that DeepSeek-V2 paper claims a KV cache size reduction of 93.3%. They don’t exactly publish their methodology, but as far as I can tell it’s something likes this: start with Deepseek-v2 hyperparameters here: https://huggingface.co/deepseek-ai/DeepSeek-V2/blob/main/configuration_deepseek.py. num_hidden_layers=30, num_attention_heads=32, v_head_dim = 128. If DeepSeek-v2 was implemented with traditional MHA, then KV cache size would be 2*32*128*30*2=491,520 B/token. With MLA with a KV cache size of 576, we get a total cache size of 576*30=34,560 B/token. The percent reduction in KV cache size is then equal to (491,520-34,560)/492,520=92.8%. The numbers I present in this video follow the same approach but are for DeepSeek-v3/R1 architecture: https://huggingface.co/deepseek-ai/DeepSeek-V3/blob/main/config.json. num_hidden_layers=61, num_attention_heads=128, v_head_dim = 128. So traditional MHA cache would be 2*128*128*61*2 = 3,997,696 B/token. MLA reduces this to 576*61*2=70,272 B/token. Tor the DeepSeek-V3/R1 architecture, MLA reduces the KV cache size by a factor of 3,997,696/70,272 =56.9X. 2. I claim a couple times that MLA allows DeepSeek to generate tokens more than 6x faster than a vanilla transformer. The DeepSeek-V2 paper claims a slightly less than 6x throughput improvement with MLA, but since the V3/R1 architecture is heavier, we expect a larger lift, which is why i claim “more than 6x faster than a vanilla transformer” - in reality it’s probably significantly more than 6x for the V3/R1 architecture. 3. In all attention patterns and walkthroughs, we’re ignoring the |beginning of sentence| token. “The American flag is red, white, and” actually maps to 10 tokens if we include this starting token, and may attention patterns do assign high values to this token. 4. We’re ignoring bias terms matrix equations. 5. We’re ignoring positional embeddings. These are fascinating. See DeepSeek papers and ROPE. - End of feed



